




.svg)









Modern on-call work exposes the real state of a system. Pager noise, late-night pages, and recurring incidents do not appear randomly. They surface because production systems are communicating weaknesses in design, observability, automation, and ownership.
For many teams, on-call becomes a survival exercise. For mature site reliability organizations, on-call becomes a feedback loop. The difference is not resilience or grit. The difference is whether stress is treated as noise or as data.
This article explains how to move from reactive on-call coverage to proactive reliability engineering, and how to turn operational stress into lasting system improvement.
Key Takeaways
- On-call stress reflects system design gaps, not individual performance
- Recurring incidents indicate missing reliability feedback loops
- Reducing on-call fatigue requires engineering change, not coping strategies
- Automation and toil reduction directly improve reliability outcomes
- Error budgets create enforceable boundaries that protect engineers
What On-Call Stress Really Means in Site Reliability Engineering

In site reliability engineering, on-call stress signals unmanaged risk. When alerts interrupt human operators repeatedly, systems are asking for structural fixes. Reliability improves when stress patterns are analyzed and engineered away.
On-call exists to protect users from system failure. In theory, it is a temporary safety net while reliability work progresses. In practice, many teams treat on-call as a permanent condition.
Stress emerges when human response becomes the primary mitigation strategy. Every alert that requires manual investigation indicates one of three things:
- The system lacks sufficient automation
- The system lacks clear ownership or context
- The system is operating beyond its reliability limits
In site reliability engineering, stress is not emotional noise. It is operational telemetry. Repeated stress points map directly to weak interfaces, unclear dependencies, and missing safeguards.
Ignoring that signal leads to burnout. Interpreting it correctly leads to system improvement.
Why Reactive On-Call Fails at Scale
Reactive on-call does not scale because humans do not scale linearly. As systems grow, incident volume increases unless reliability work reduces failure frequency. Without feedback loops, on-call becomes unsustainable.
Reactive on-call focuses on response speed. It optimizes how quickly a human can wake up, investigate, and mitigate an issue. While response speed matters, it does not reduce the likelihood of future incidents.
At small scale, this approach appears to work. At larger scale, it collapses under its own weight.
The failure modes are predictable:
- Alert fatigue reduces signal quality
- Cognitive load increases during incidents
- Knowledge silos form around frequent responders
- Engineers spend more time reacting than improving
When teams only optimize response, incidents become normalized. Each page feels urgent, but no page feels actionable beyond immediate mitigation. Reliability stagnates while stress accumulates.
True scalability requires reducing the number of incidents that reach humans at all.
The On-Call to Reliability Feedback Loop
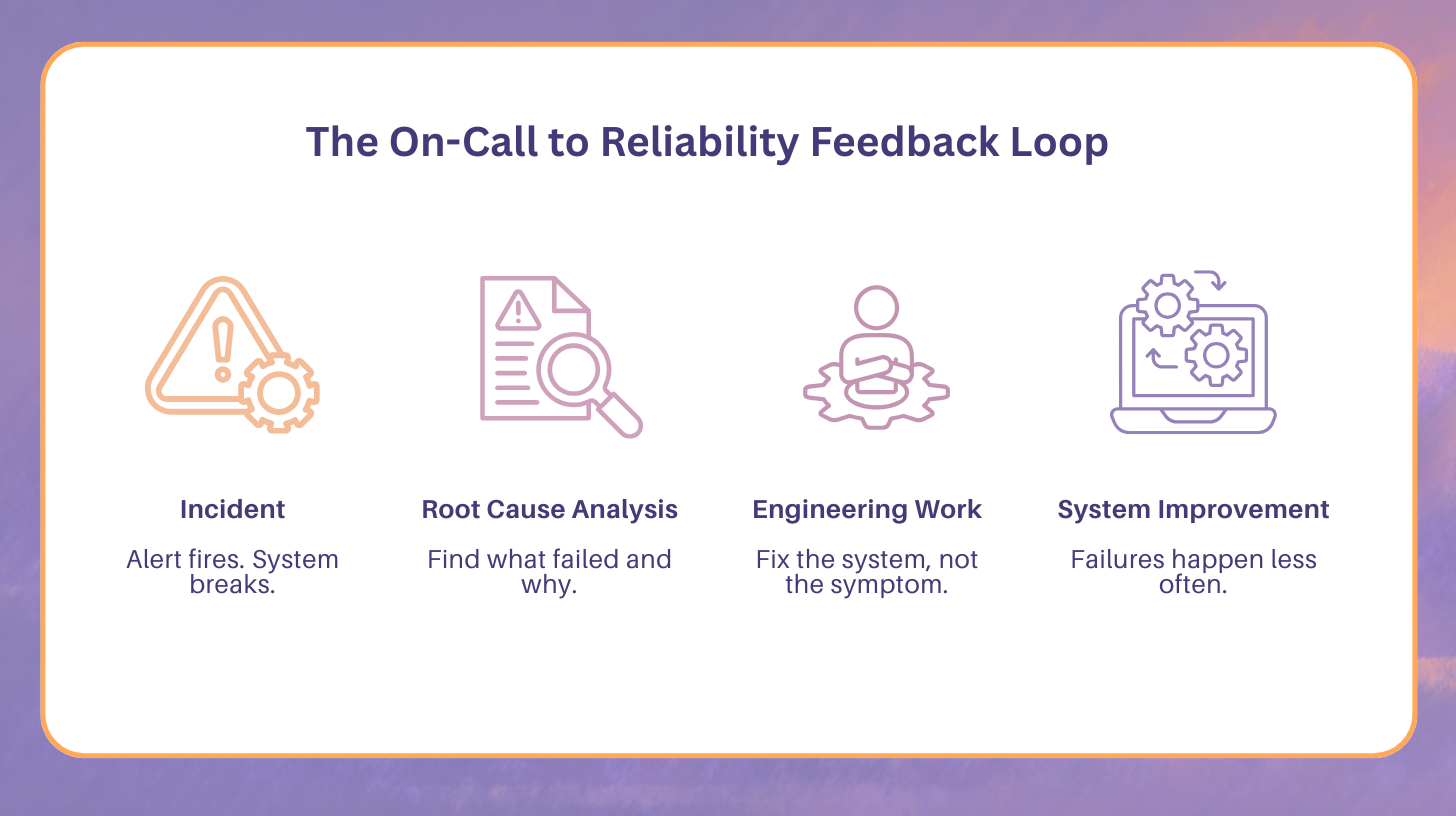
On-call improves reliability only when incident data feeds engineering priorities. Incidents must generate learning, not just resolution. Feedback loops transform operational pain into system resilience.
Every incident produces data. That data includes timestamps, affected components, escalation paths, and mitigation steps. More importantly, it reveals where assumptions about the system failed.
A reliability-focused feedback loop follows a consistent pattern:
- An incident occurs and is mitigated
- The incident is analyzed for root causes
- Findings are translated into engineering work
- Changes reduce the likelihood or impact of recurrence
When any step is skipped, stress compounds. When all steps are followed, reliability improves and on-call load decreases.
This loop turns incidents into investments. Each page becomes a signal that funds future stability.
Turning Incidents into System Improvements
System improvement begins where manual intervention repeats. Root causes live beneath symptoms and alerts. Post-incident analysis must result in code, configuration, or process change.
Not all incidents deserve equal attention. Reliability engineering focuses on patterns, not one-offs.
Effective incident analysis asks structured questions:
- Why did this incident reach a human?
- Why was detection delayed or noisy?
- Why did mitigation require specialized knowledge?
- Why did safeguards fail to contain impact?
Answers should never stop at human error. Humans interact with systems as designed. If intervention was required, the system permitted it.
System improvements often fall into clear categories:
- Alert tuning to reduce noise
- Automation of known remediation steps
- Redesign of brittle dependencies
- Improved observability for faster diagnosis
- Clearer ownership boundaries
When incident analysis produces backlog items, reliability becomes measurable progress rather than aspiration.
Reducing Toil Through Automation
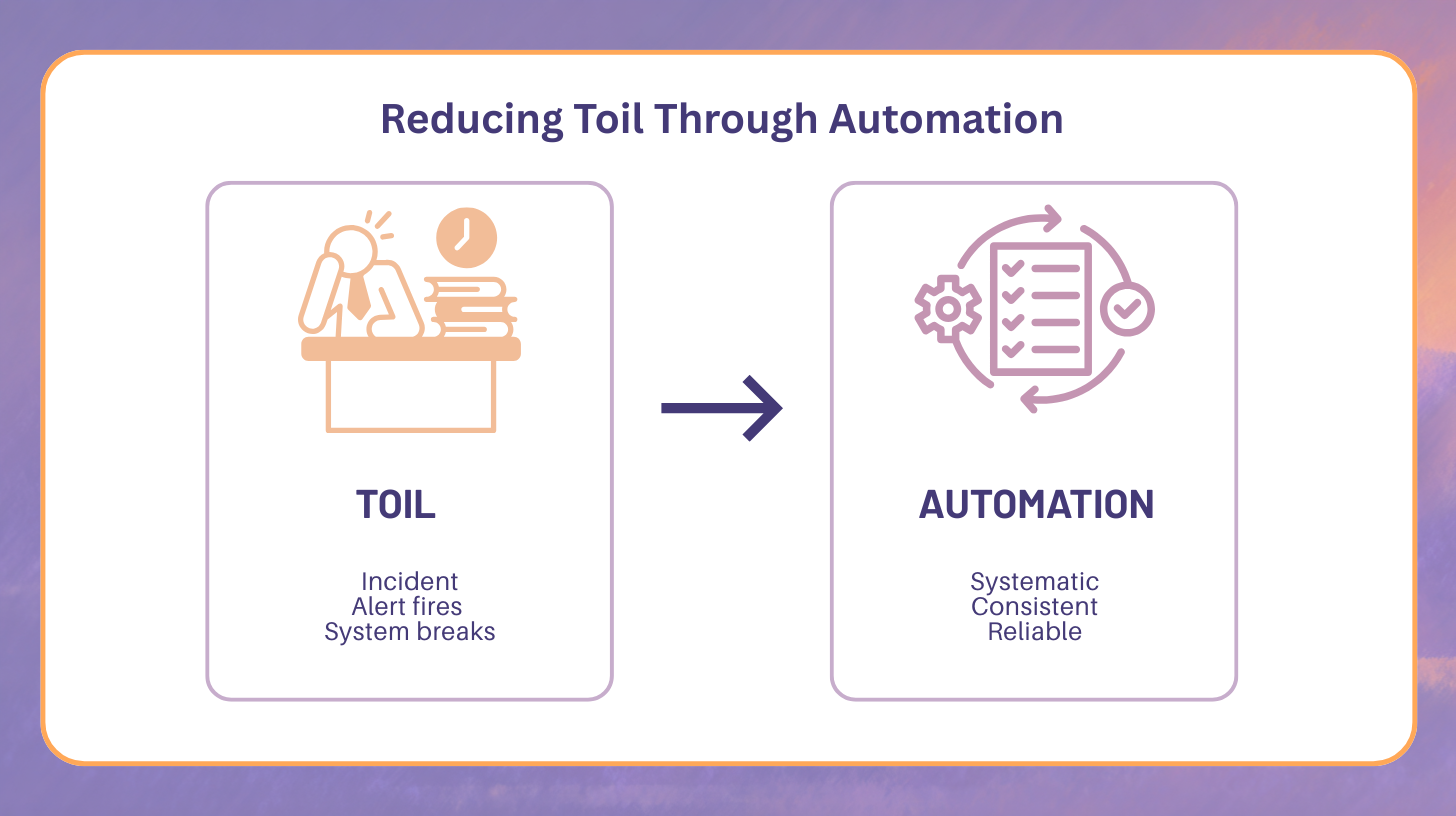
Toil is repetitive operational work that produces no lasting value. High toil directly correlates with on-call fatigue. Automation converts human effort into system reliability.
Toil is not just inconvenient. It is a reliability risk. Every manual step introduces variability, delay, and opportunity for error.
Examples of toil include:
- Restarting services manually
- Applying known configuration fixes
- Running the same diagnostic commands repeatedly
- Coordinating handoffs across teams
Automation eliminates toil by encoding operational knowledge into systems. This does not remove human judgment. It removes unnecessary human involvement in predictable scenarios.
Each automated task reduces future on-call load. Over time, automation compounds. Teams that invest consistently experience fewer pages and faster resolution when pages do occur.
Reliability engineering treats automation as preventative care, not optimization.
Using Error Budgets to Protect Engineers
Error budgets translate reliability goals into enforceable limits. They balance feature velocity with system stability. Error budgets protect engineers from unsustainable on-call demands.
Without explicit limits, systems drift toward fragility. Error budgets define how much unreliability is acceptable over a given period. When that budget is exhausted, priorities shift.
This mechanism creates alignment:
- Product teams understand reliability tradeoffs
- Engineering teams gain leverage to prioritize stability
- On-call load becomes a measurable constraint
Error budgets also externalize stress. Instead of engineers absorbing pain silently, the system communicates when it is overextended. That signal triggers action before burnout occurs.
Used correctly, error budgets transform reliability from a moral argument into an operational contract.
Tooling That Supports Reliability, Not Just Alerts
Effective on-call tooling provides context, ownership, and learning. Alerts without context increase stress without improving outcomes. Reliability tooling should shorten feedback loops, not just notify humans.
Alerts are only useful when they accelerate understanding. Tools that flood engineers with notifications without clarity amplify stress.
Reliability-focused tooling supports the full incident lifecycle:
- Clear alert ownership and routing
- Immediate context from monitoring and logs
- Structured incident coordination
- Automatic capture of incident data for analysis
The goal is not faster paging. The goal is faster learning. When tools connect incidents to follow-up work, on-call becomes a driver of improvement rather than interruption.
Tooling should make the right thing easier than the wrong thing.
From On-Call Survival to Reliability Culture
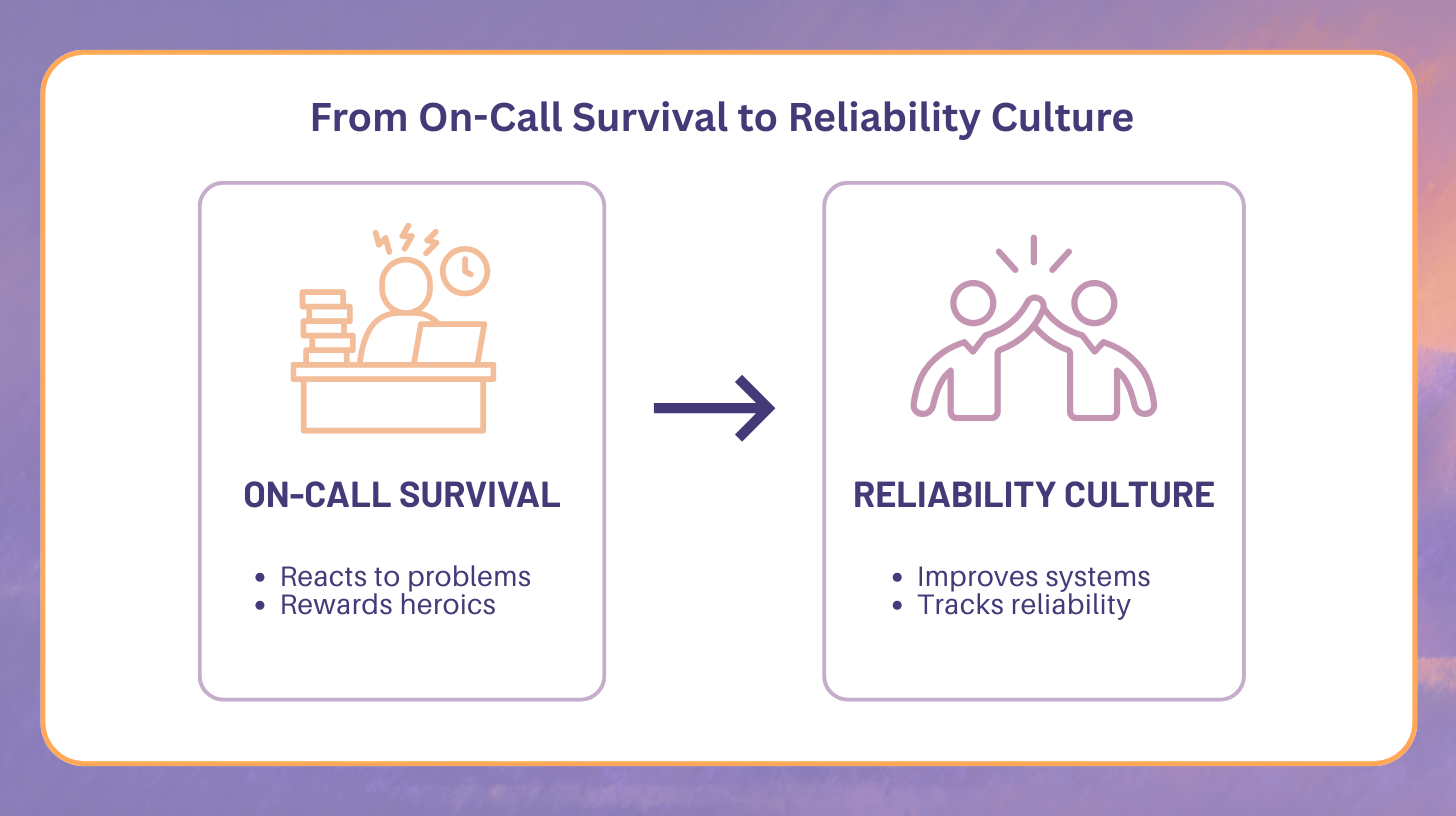
Reliability culture treats stress as system feedback. Engineering teams improve systems instead of absorbing pain. Sustainable on-call emerges from deliberate reliability investment.
Culture changes when incentives change. Teams that reward heroics unintentionally encourage fragile systems. Teams that reward reliability work reduce the need for heroics altogether.
A reliability culture shares several traits:
- Incidents are discussed without blame
- Improvements are prioritized over temporary fixes
- On-call health is monitored as a system metric
- Reliability work is visible and valued
Over time, this culture produces calmer on-call rotations, more predictable systems, and engineers who can focus on building rather than firefighting.
Turning Stress into Reliability at Scale
On-call stress does not disappear on its own. It fades only when systems improve. At Rootly, we have seen that the teams who suffer least are not the ones with the toughest engineers, but the ones with the strongest feedback loops.
When on-call pain is treated as data, reliability accelerates. When incidents inform engineering priorities, systems become quieter. When automation replaces toil, engineers reclaim their time and focus.
Reliability is not about working harder. It is about listening better to what systems are already telling us.




