
Atlassian is shutting Opsgenie down April 2027 and they want you on JSM, but JSM tracks incidents, it doesn't run them.
Resolve incidents faster, improve system resilience, and streamline technical operations; from alert to resolution and post-incident learning, all in one platform with Rootly.
Jira Service Management
Alerts route through static rules you maintain by hand; the rule keeps paging the wrong person until someone fixes it.
A ticket is created. The real response happens elsewhere while someone keeps the ticket in sync manually.
Updates and communications are manual. Someone has to stop responding to write it, and send it, over and over.
Investigating RCA isn't something JSM does. It holds the ticket and whatever notes people add.
The retro depends on someone reconstructing everything from memory, then follow-ups become more tickets.
Rootly
Rootly knows who owns the service, who's on call, and who needs to be paged, so the right person is paged first time.
Declaring an incident opens a Slack channel with roles assigned, severity set, responders in, and all the context.
Rootly drafts audience-specific updates and posts them everywhere they're needed, including the status page.
Rootly AI investigates from the first alert, surfacing probable root cause with a suggested fixes.
The retro is generated automatically, with all the context, while action items are assigned and tracked to completion.

Resolve incidents faster, improve system resilience, and streamline on-call operations. On-call, incident response, retrospectives, status pages, workflows, follow-ups, and so much more, all at half the price.

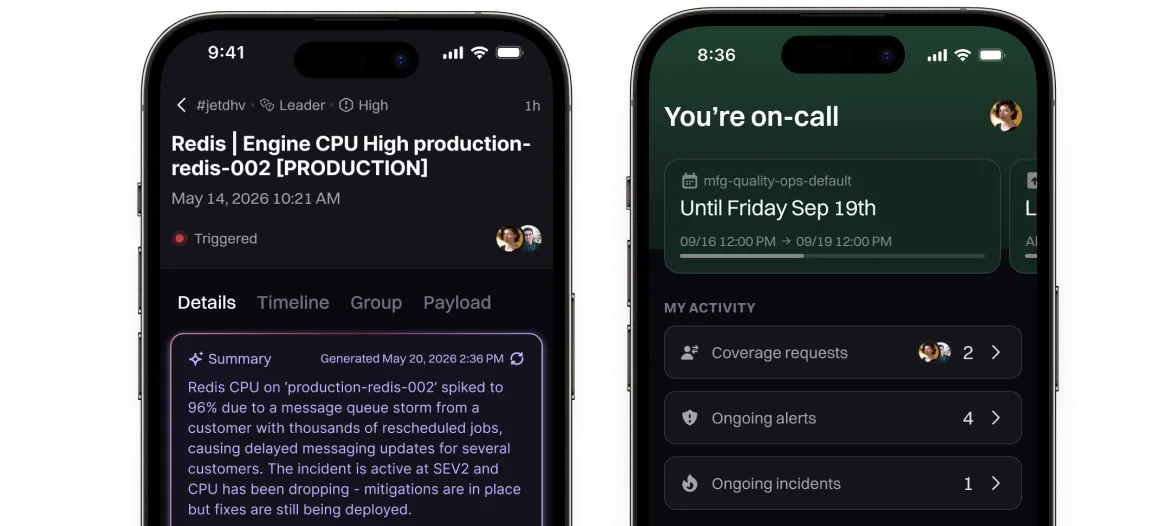
Rootly is a purpose-built incident management platform for the entire incident lifecycle.
Run incidents end-to-end, with all the right people, without leaving Slack.
No more using services as a workaround. Page teams, services, and more.
No extra rota, no manual cleanup when shadowing ends.
Overrides and requesting coverage made easy, including your PTO and holiday schedule.
No more manually calculating who should get paid with spreadsheets.
The basics done right. Setup your first schedule or escalation in minutes.
Sync Slack user groups like @team-infra with on-callschedules.
Never get caught with no one on call.
Automatically rotate on-call responsibilities, so no single team member is overwhelmed.
Consistency matters, ensuring escalation policies have enough levels.
Inform customers in real time, reduce support noise, and build trust during downtime.
Mention @Rootly to get answers and drive actions without leaving the channel.

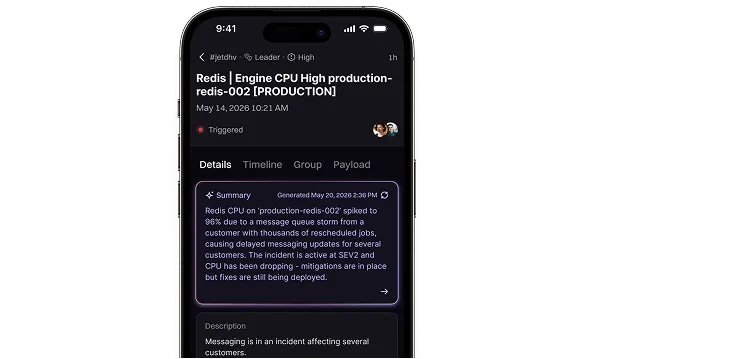
Ask questions and direct actions right from your finger tips, from anywhere in the world.
Stay a head with suggested troubleshooting, actions, and who to page.
A dedicated meeting scribe that captures all context so nothing slips through the cracks.
Automated root cause analysis complete with alert correlation and suggested fixes.
Quickly understand historical incidents, how they relate, and how they were resolved.
AI-powered retrospectives from contributing factors to timeline generation.
AI that’s not a black box. View and edit the prompts that return the data you need.
Plugged into your IDE and CLI, so you can set config, get answers, and resolve incidents in seconds—right where you work.

Reporting and metrics from alerts to on-call readiness and everything in between.
An open source tool that looks for early warning signs of overload in your on-call engineers.

A fellow-led community designed to redefine reliability engineering.
Equip responders with the skills, confidence, and experience to succeed when it matters most.
Any team, at any stage, any AI comfort level.



Rapid incident response and resolution
JSM
Rootly
Purpose-built for incident response
Coordinated and automated incident response.
Native alert integrations
Datadog, Grafana, Prometheus, Honeycomb, etc.
On-call scheduling
Create and manage rotation schedules.
Native shadow rotations
No extra rotation, no manual cleanup when shadowing ends.
Coverage requests
Request cover and have the system find someone available.
On-call pay calculator
Automated on-call compensation calculated.
Automated gap detection
Never get caught with no one on call.
Escalation policies for teams, individuals, services
Escalations that page the right person, every time.
Slack-native incident management
Run incidents end-to-end without leaving Slack.
Automatic role assignment
Assign incident commander, comms lead, etc. automatically.
AI Agent in Slack
Ask questions about live and historical incidents.
Automated stakeholder updates
Structure communications sent automatically.
Native service catalog
Teams, services, and ownership modelled once.
Paid add-on
Status pages
Internal and external status pages.
Paid add-on
Config maintenance overhead
How much effort to maintain as your org scales.
High - legacy UI, compounds at scale
Low - abstracted logic, flexible workflows
Mobile app with AI
Native mobile app for paging and response, incl. AI.
AI SRE (auto-RCA)
AI that automates root cause analysis and suggests fixes.
AI summaries + Retrospectives
Auto-generate incident summaries and retrospectives.
SSO / SAML
Single sign-on via SAML.
Paid add-on
SCIM provisioning
Automatic user provisioning and de-provisioning.
Paid add-on
Team-scoped permissions
Restrict access and actions by team.
Edge connector
Outbound agent for internal systems that cannot acceptinbound internet connections.
Audit logging
Track changes and actions across the platform.
Paid add-on
Contractual SLA
Guaranteed uptime commitment.
up to 99.9%
up to 99.99%
Everything you need to know about Rootly vs. Jira Service Management.
Can Jira Service Management do incident management?
JSM can log incidents as tickets and, since absorbing Opsgenie, includes basic on-call and alerting. But across the workflows that decide an incident; the ownership-based paging, live response coordination, automated comms, root-cause investigation, and retrospectives, JSM holds a record while engineers do the work manually across Jira, Slack, and Confluence. Rootly runs each of those workflows natively.
What's the real difference between JSM and Rootly?
JSM is an ITSM and ticketing platform that can track incidents. Rootly is a dedicated incident platform that runs them. In practice, JSM routes alerts by static rules, Rootly routes by service ownership; JSM coordinates response in a ticket plus scattered tools, Rootly runs it in Slack or Teams with one live timeline; JSM has no incident investigation, Rootly has AI SRE; JSM retros are manual, Rootly's are generated and tracked.
Should I move from Opsgenie to JSM?
Short answer is no. But it's worth doing the math first. Capabilities included in Opsgenie Standard; post-incident analysis, stakeholder notifications, longer alert retention, require JSM Premium at $51.42/agent/month, a 158% increase. Many teams use the forced Opsgenie migration as the moment to adopt a dedicated incident platform instead of moving within Atlassian. They use the time to upgrade, not move laterally.
Does JSM have an AI for incident investigation?
JSM's AI is built for the service desk; virtual agents that triage and deflect support requests. It does not investigate production incidents or surface root cause. Rootly AI SRE is purpose-built for incident investigation. It correlates alerts, factors in recent deployments and dependencies, and surfaces likely root cause with confidence scores and suggested fixes, while the incident is still active.
Can I keep using Jira and Confluence with Rootly?
Yes. Rootly connects to your Atlassian tools in a few clicks. Incidents run in Rootly; follow-ups sync to Jira; retros export to Confluence. Leaving JSM for incident management doesn't mean leaving the Atlassian suite.
Is Rootly a replacement for JSM?
Not for ITSM. JSM is a strong service desk for requests, approvals, and SLAs, and Rootly doesn't replace that. Rootly replaces the part of JSM that was never its strength, running incidents. Most teams keep both.
How long does it take to get started?
Full JSM ITSM implementations often run 3–6 months and usually involve a certified Atlassian Partner. Most teams are live on Rootly within a week, with no professional services required.





.svg)






