




.svg)









Modern software does not sleep. Customers expect services to be reliable, fast, and available from any region and at any hour. Most companies now sell and support users across many time zones, which means a production incident cannot wait for someone to wake up in San Francisco or log in from Berlin. Incident response must follow the sun because the business already does.
Teams that once relied on a single on-call engineer for their entire stack now face a different operational reality. Services have multiplied. Traffic patterns differ by region. External dependencies introduce new points of failure. Regulatory compliance dictates how and when information can move across borders. The challenge is no longer having one person carry a pager. The challenge is designing a distributed on-call model that works for the organization as a whole.
Engineering and SRE groups in large organizations are investing in distributed and global on-call programs to provide continuous reliability while protecting responder health and maintaining cohesive ownership across teams and time zones.
Why Global On-Call Has Become the Default
There was a time when on-call was synonymous with night pages, sleep interruptions, and heroic individual effort. Whenever a checkout service failed or a degraded database started affecting response times, one person would drop everything and respond. This model emerged organically because early technology companies sold regionally, often within the same time zone.
Today the business context is different in three key ways.
Global customers require global availability
Most companies are no longer tied to one geographic market. Even startups ship to customers across multiple continents shortly after launch. In industries like finance, SaaS, gaming, commerce, and logistics, users interact with services continuously. If customers cannot use a system for even a short period, the business absorbs the impact immediately through:
- failed transactions
- customer service spikes
- revenue loss
- churn or negative reviews
- contractual penalties
In enterprises that serve millions of users, incidents can quickly escalate into board-level or regulatory concerns.
Systems are distributed, complex, and interdependent
Enterprises rarely operate a single system. They operate many services that communicate with each other and depend on external vendors. In practice this means a disruption in one region may not stay local. A payment processor outage in Singapore can affect fulfillment applications in Europe or dashboards used by customer success teams in North America.
Operational handoffs must mirror reality
Global commerce never stops. A quiet night in California is the peak hour for users in Sydney. A holiday in London is a working day in Toronto. A product launch in Tokyo may trigger increased load in São Paulo. Distributed on-call is therefore not a luxury. It is the operational expression of how modern businesses function.
What Distributed and Global On-Call Really Means
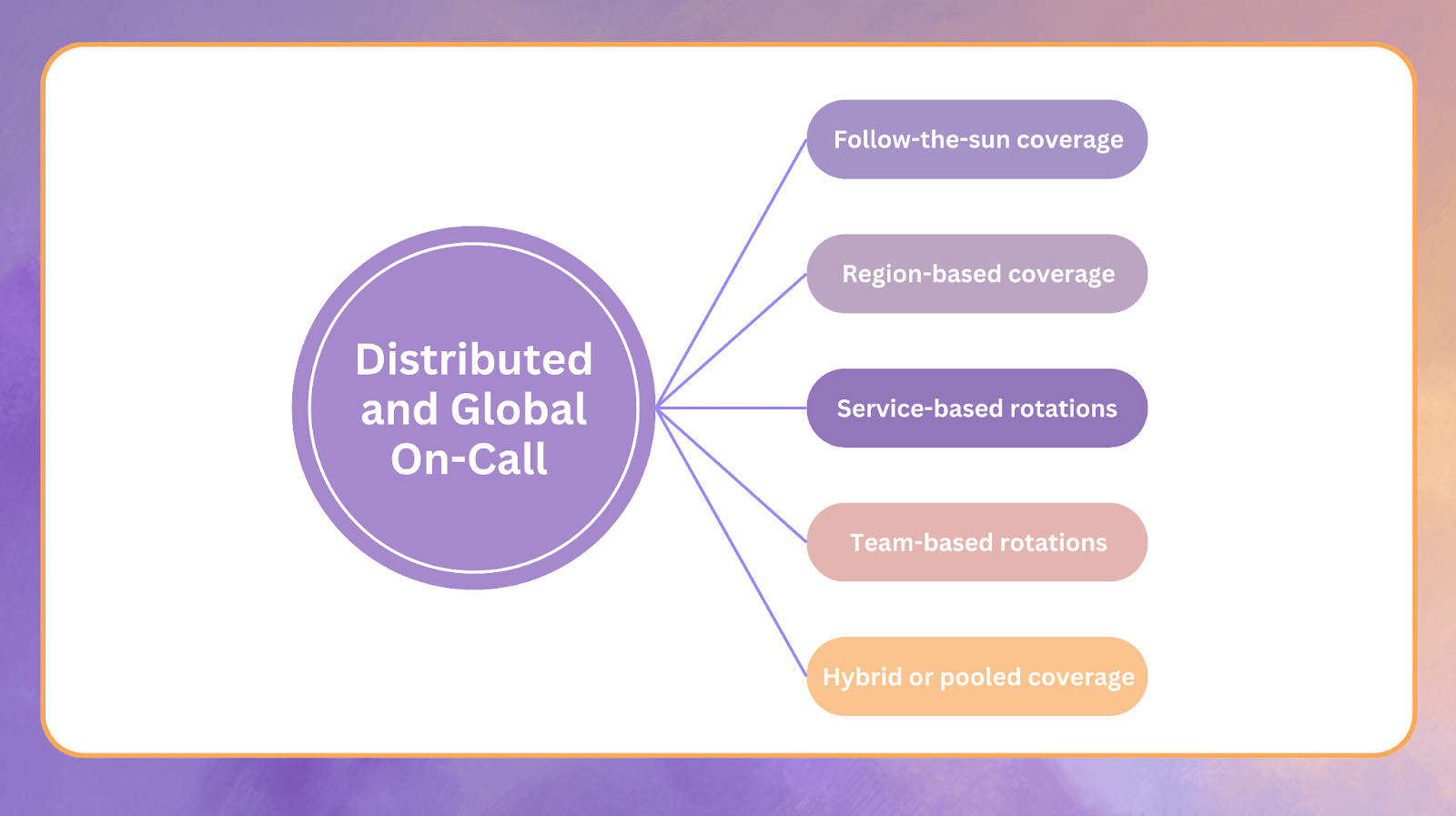
Distributed on-call describes a staffing and operational model in which incident response responsibilities are divided across regions, time zones, and often specialized teams. It is not simply a larger rotation or a longer schedule. It is a structural shift in how reliability is achieved.
There are five common coverage models used by distributed teams.
Follow-the-sun coverage
Follow-the-sun is a scheduling strategy in which primary responders rotate by region. When a shift ends, responsibility moves to the next time zone where responders are working normal business hours. This eliminates night paging and spreads operational load evenly across the globe.
Region-based coverage
Region-based models assign responders to the services or infrastructure that correspond to specific geographic markets. This is common in commerce, payments, and telecommunications because performance and compliance requirements vary by region.
Service-based rotations
Enterprises often structure on-call around critical services such as payments, search, identity, or data pipelines. A team may operate two layers of coverage for its service. For example, a primary responder handles alerts first, while a secondary responder acts as backup.
This is the most common pattern seen in large enterprise environments.
Team-based rotations
Some enterprises page teams independent of services. For example, a database engineering group or a mobile platform team might be paged regardless of which product surfaces are affected. Older incident management tools do not support this model natively, which historically forced administrators to create manual escalation workarounds. Modern platforms such as Rootly support team-based rotations out of the box because enterprises depend on them.
Hybrid or pooled coverage
Hybrid pools are used when specialized services or small responder groups need temporary support during high-volume periods, holidays, or weekends. Hybrid pools introduce redundancy without requiring a full global staffing model.
Operational Challenges of Global Coverage
Deploying 24/7 coverage introduces a different category of complexity. The challenges are no longer confined to the individual responder but instead involve communication, coordination, and operational design.
Mixed maturity across services
Large enterprises run hundreds of services owned by dozens of teams. Some achieve four nines of availability while others are newly launched, undergoing migration, or carrying technical debt. Reliability is uneven not because some teams are less capable but because the underlying services vary by:
- Architecture
- demand patterns
- geographic footprint
- infrastructure stack
- external dependencies
Distributed on-call has to accommodate these differences without creating unfair load on any single region or team.
Global SLOs are not enough
A global service level objective may indicate that a system is meeting its availability target even while a significant subset of regional users are impacted. Consider a service that meets a 99 percent global SLO while users in two regions experience degraded performance. The global average hides the regional outage. Enterprises therefore introduce geography as a dimension of reliability.
Escalation policies become fractal
At enterprise scale, escalation policies resemble nested structures. A global escalation policy contains regional policies, which contain team policies, which contain subteam policies. An incident can escalate vertically to senior engineers, horizontally to other functions, or laterally to different services depending on impact. This structure allows large teams to coordinate without overwhelming a single responder.
Identifying the right people to involve
When a service experiences an incident, the initial alert may surface in one team, but the root cause may reside somewhere else entirely. At scale, this becomes one of the most difficult aspects of incident response. Teams at Meta have experimented with AI systems that narrow the root cause search space by correlating diffs, logs, changes, and past incidents. Platforms like Rootly apply similar ideas by identifying responders who have worked on similar incidents previously.
Coordinating non-engineering response
Incidents that affect customers often require contact with support, account management, or customer success. These teams handle incoming questions and work to manage customer expectations while engineers mitigate the issue. Enterprises sometimes maintain predefined guidelines that specify when to notify which groups. For example, an incident affecting a top customer triggers immediate notification for their account team.
External communications require guardrails
Enterprise responders cannot update status pages or external channels without coordinating with legal, PR, or compliance teams. Communication must be consistent, accurate, and timely. Distributed on-call introduces additional complexity because different teams may be awake and operating at different times.
Vendor and tool sprawl
At enterprise scale, the number of vendors that touch incident response increases. Organizations must coordinate across:
- monitoring and observability
- Alerting
- collaboration and messaging
- ticketing and change management
- Retrospectives
- security tools
- compliance systems
Rootly helps enterprises consolidate alerting, incident management, retrospectives, and on-call scheduling into a single platform to reduce fragmentation and interoperability work.
Structuring Rotations for Continuous Coverage
Once the need for distributed on-call is clear, teams must choose how to structure rotations. The choice depends on three factors.
1. Customer geography
Traffic patterns dictate when incidents matter most.
2. Responder geography
Coverage depends on staffing and expertise distribution.
3. Service ownership boundaries
Ownership maps to the organizational chart and determines how responsibility flows.
Follow-the-sun rotations
Follow-the-sun eliminates night paging by passing ownership between time zones at scheduled handoff times. The success of this model depends on reliable handoffs. If information does not transfer correctly, the next responder may spend precious time reconstructing context instead of mitigating.
Service-based rotations
This model assigns responders to individual services. Enterprises with complex payment architectures, search platforms, or distributed data systems often adopt this because ownership is clean. The payments team knows payments, the identity team knows identity, and so on.
Team-based rotations
Enterprises that organize ownership around infrastructure or platform layers use team-based rotations. For example, a database reliability team may own operational response for database migrations across products. Older vendors did not support team-based alerting natively, which created administrative overhead. Rootly supports team rotations so enterprises can mirror their organizational model without manual effort.
Hybrid pool coverage
Hybrid pools solve gaps during weekends, holidays, and peak load seasons. For example, a retailer may create a hybrid pool for the fourth quarter of the year when load peaks due to holiday commerce. Hybrid pools allow specialized teams to avoid 24/7 staffing while still ensuring coverage.
Escalation Policies for Distributed Teams
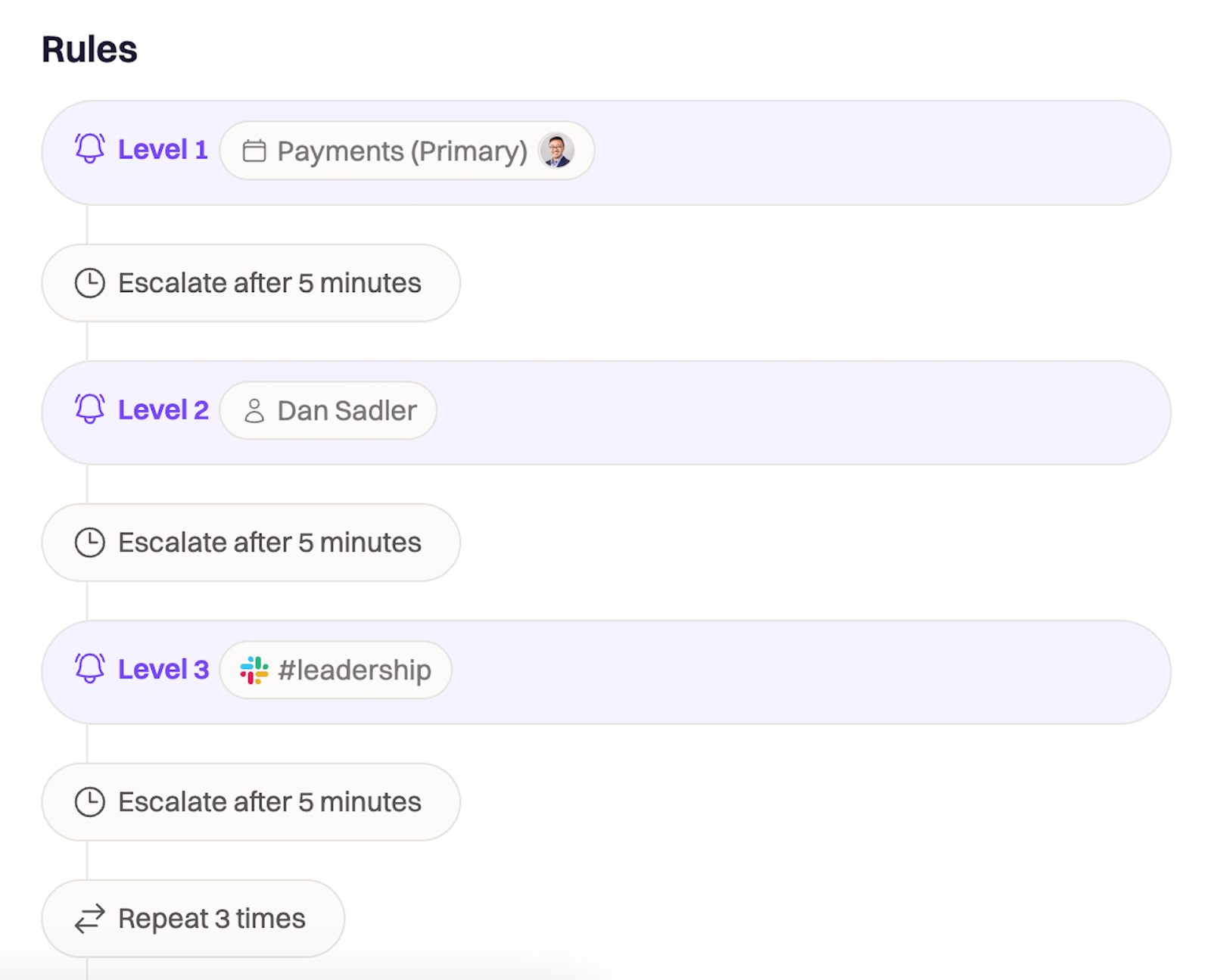
Escalation policies determine how alerts move through responders when the primary responder cannot acknowledge or resolve them. Distributed teams rely on escalation policies to ensure that incidents are not dropped during region changes or handoff windows.
Why escalation policies exist
It is not enough to have a single person available. Phones die, networks disconnect, accidents happen, or responders may be in environments where acknowledgment is impossible. Escalation policies exist to guarantee that alerts are acknowledged and handled correctly.
Round Robin to reduce alert fatigue
Round Robin escalation policies distribute alerts among multiple responders rather than funneling them to a single individual. This reduces alert fatigue and distributes load evenly. Article 1 explored the scenario of a responder whose Saturday evening is repeatedly interrupted by alerts. When incidents wake someone up multiple times in a night, burnout follows quickly. Distributed teams benefit from Round Robin because alert load is inherently uneven across time zones.
There are two main Round Robin variants.
Alert-based Round Robin
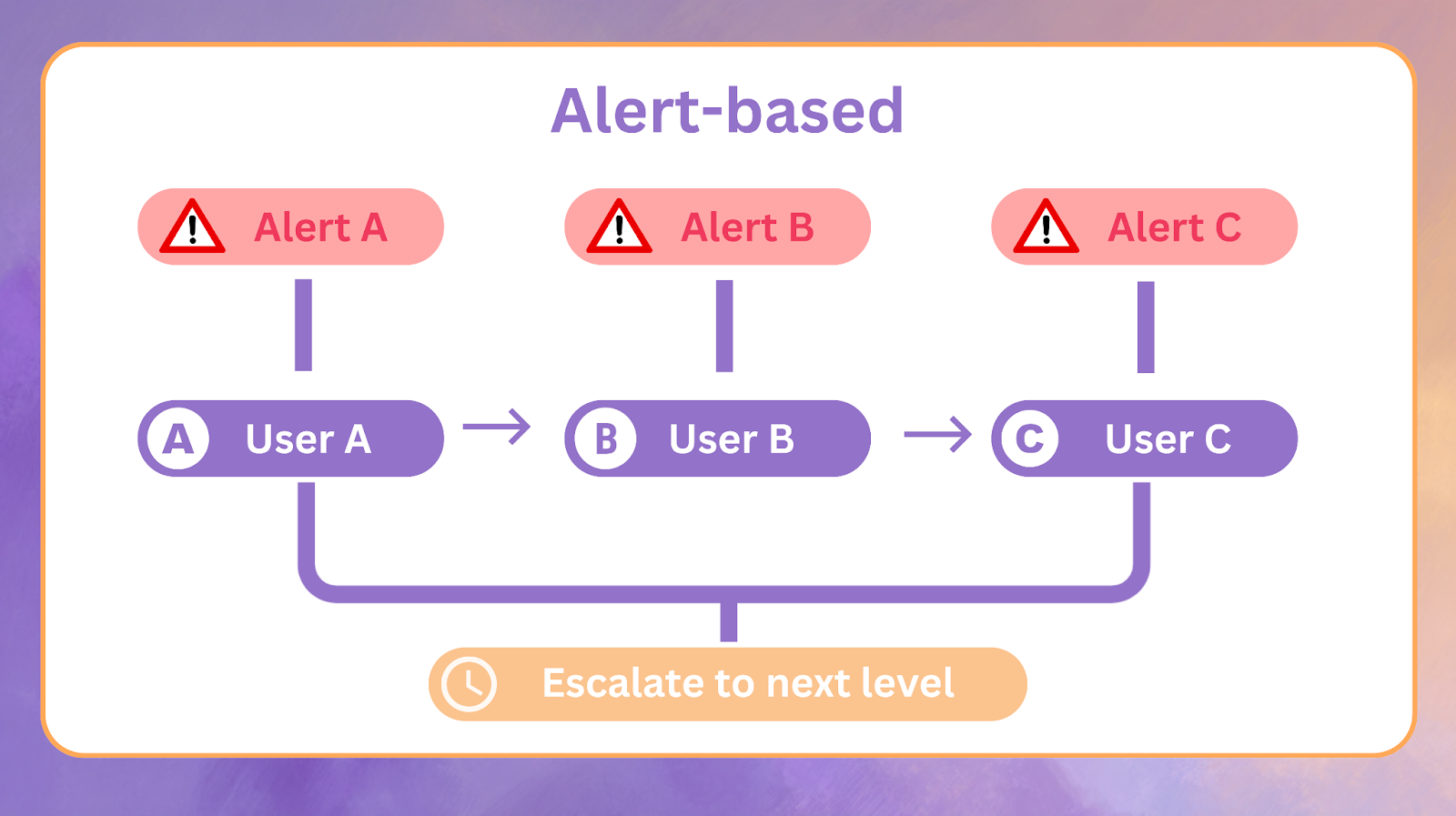
Each alert is assigned to a responder in sequence. If a responder does not acknowledge within a configured time window, escalation jumps to the next level. Alert-based Round Robin spreads responsibility evenly across the level.
Cycle-based Round Robin
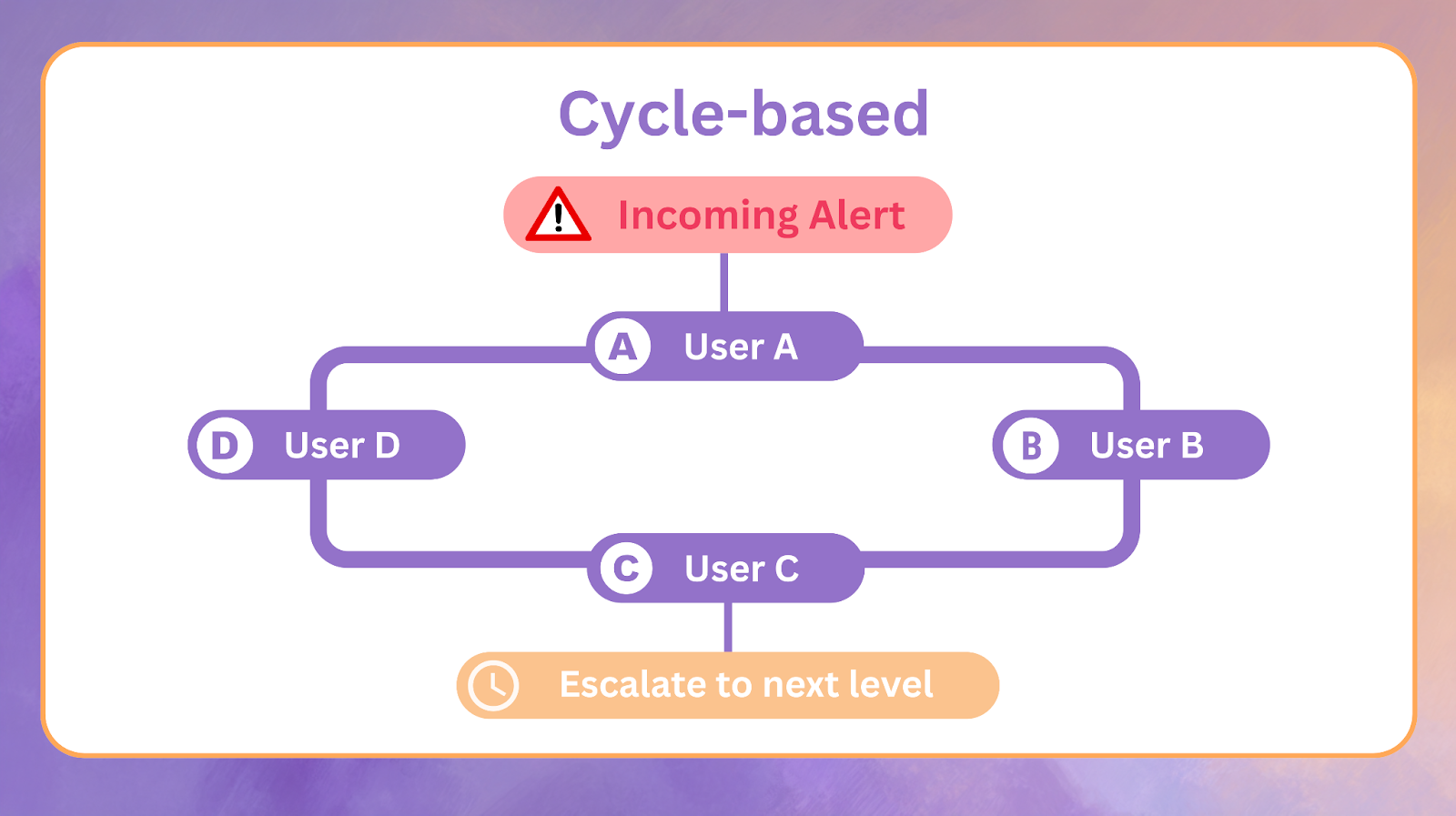
Instead of escalating to the next level, the alert moves to the next responder in the Round Robin cycle until the cycle completes. Escalation only occurs after the entire cycle fails. Cycle-based models reduce overhead on higher escalation levels.
Rootly supports both models natively and applies them per escalation layer.
Escalation complexity in enterprises
In enterprises, escalation policies resemble nested patterns. A global escalation policy might send notifications to a regional dispatch, which escalates to team leads, which escalates to specialized subteams. These layers allow enterprises to manage incidents involving thousands of services and hundreds of engineers without routing everything through a central group.
Handoffs as the Critical Unit of Reliability
Distributed on-call shifts reliability from individual responders to handoffs. When an incident crosses time zones, the next group must inherit context, state, and progress without rework. Poor handoffs cause repeated diagnosis, wasted time, and unnecessary escalations.
Effective handoffs include:
- current status
- known root cause hypotheses
- mitigation attempts and outcomes
- Blockers
- customer impact summary
- communication channels in use
- ownership for next steps
High-performing distributed teams create artifact-led handoffs. Artifacts include timelines, runbooks, incident channels, and retrospective notes. Rootly automates incident timelines and provides state snapshots that allow responders in other regions to resume work without reconstructing context.
Managing Alert Load and Responder Health
Distributed on-call only works if responders remain healthy and engaged. It is easy to transfer operational burden to another region and assume success. In reality, global distribution only changes who wakes up at night if programs are not designed carefully.
Alert fatigue is a common failure mode. If alerts arrive frequently, responders eventually lose the ability to maintain focus or make sound decisions. Article 1 emphasized that responders should not remain in rotation during weekends or while on vacation. Distributed organizations often make the mistake of keeping out-of-office responders in the rotation because they assume someone else will handle the alert anyway. This creates noisy escalation patterns and disrupts responders during time off.
Best practices include:
- Remove out-of-office (OOO) responders from rotations
- avoid full team coverage during weekends
- balance coverage across holidays and cultural calendars
- ensure redundancy for specialized skills
- create alert budgets for noisy services
Hybrid pools are useful for weekend and holiday support because they spread load instead of forcing primary responders to remain available during rest periods.
Security and Compliance for Distributed On-Call
Incident response often touches sensitive systems and confidential data. Distributed teams introduce additional layers of security and compliance requirements.
Least privilege access
Enterprises enforce least privilege access so responders only see or modify what they need to resolve incidents. Incident management and on-call systems must offer granular role based access control. Rootly provides granular RBAC so enterprises can restrict write access to incident declarations, communication channels, retrospectives, and on-call scheduling.
Dedicated security workflows
Security incidents often follow separate workflows that include legal and compliance reviews. Rootly allows enterprises to define specialized workflows for security events and tailor incident declaration forms accordingly.
Vendor security and certifications
Large enterprises require vendors to meet compliance frameworks such as SOC2, ISO, and GDPR, and to maintain multi cloud reliability. Rootly operates on AWS and GCP with a 99.99 percent SLA, making it suitable for enterprises that run multi cloud deployments.
Data residency and geography
Governments increasingly regulate where data may be stored or transmitted. Distributed incident workflows must be compatible with regional data residency rules.
Automation and AI for Distributed Response
At enterprise scale, automation is not primarily about efficiency. It is about compliance, correctness, and speed. Distributed on-call requires automation because humans cannot be online at every handoff boundary, and manual coordination introduces risk.
Common automations include:
- routing alerts to correct regions
- notifying specific Slack or Teams channels during severity events
- generating incident timelines automatically
- updating tickets and action items in systems such as Jiraattaching retrospectives to the correct services
- identifying likely responders based on past incidents
Measuring Success in Distributed On-Call
Traditional metrics such as MTTR remain important, but distributed teams need additional signals to measure the effectiveness of their on-call program. There are three categories of metrics worth tracking.
Operational metrics
Operational metrics for distributed on-call programs often include MTTR, MTTD, escalation depth, the number of ownership transfers per incident, and the percentage of incidents resolved within a region versus those that require cross-region escalation. Ownership transfers are particularly important to monitor in distributed teams because each transfer introduces latency and additional operational risk.
Health metrics
Health metrics for distributed on-call programs often focus on alert load distribution across responders, nighttime alert counts, holiday and weekend coverage fairness, the number of out-of-office responders remaining in rotation, and regular on-call morale surveys. Distributed on-call cannot succeed if it damages morale or retention.
Benchmark data
An analysis of approximately 150,000 high severity enterprise incidents provides useful reference points for distributed on-call programs. About 8 percent of incidents were mitigated within 30 minutes, 22 percent within one hour, 15 percent within one to two hours, and 55 percent took more than two hours to mitigate. Follow up actions and retrospectives were typically slower. Approximately 36 percent were completed within two weeks, 23 percent within one month, 16 percent took more than one month, and 25 percent were incomplete or missing data. These benchmarks help organizations evaluate whether distributed on-call practices accelerate or hinder productivity over time.
Maturing Into Distributed On-Call Capabilities
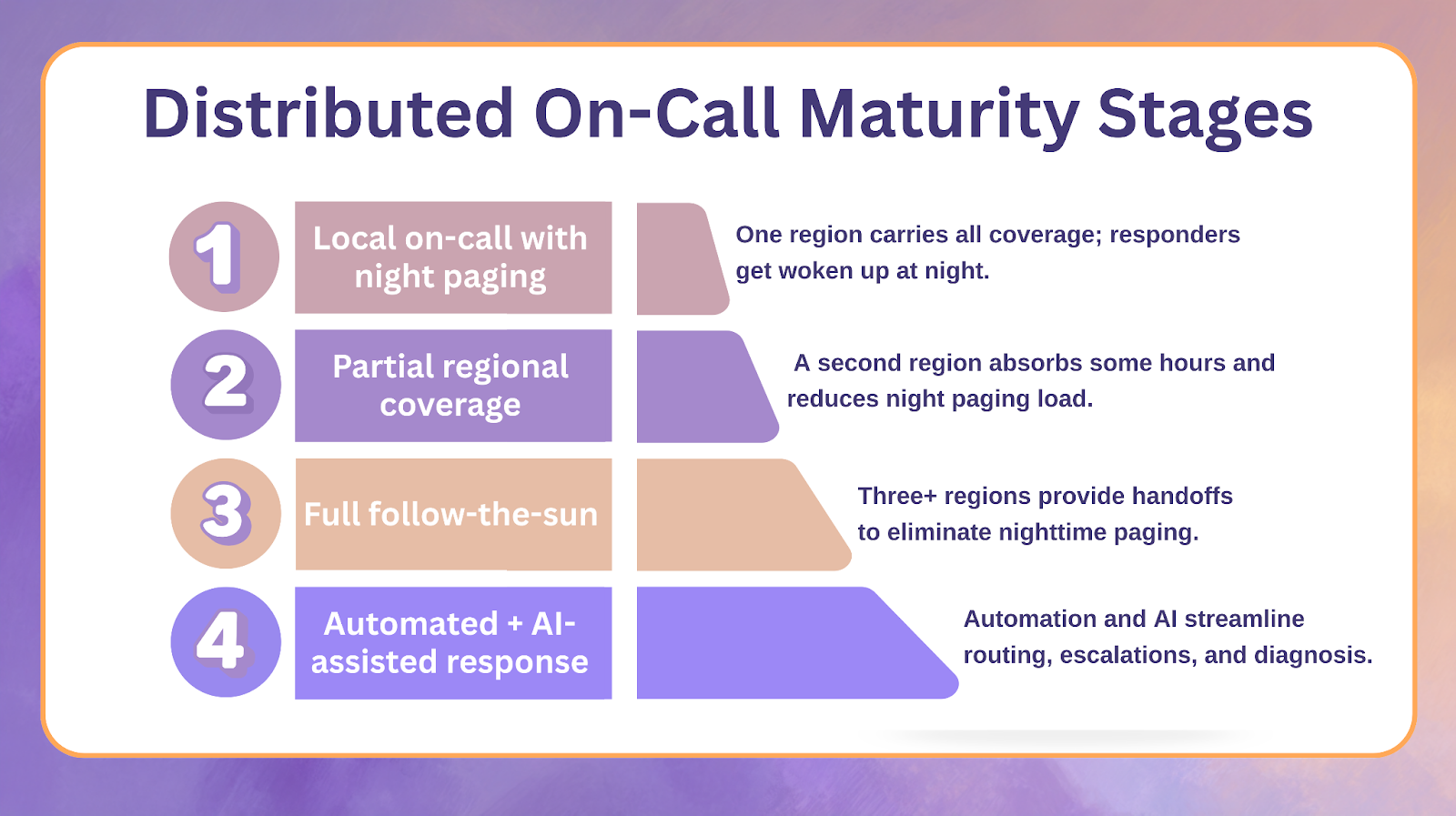
Organizations rarely adopt distributed on-call in a single leap. They pass through maturity stages.
Stage 1: Local on-call with night paging
One region carries primary coverage. Night paging interrupts responders and increases burnout risk.
Stage 2: Partial regional coverage
A secondary region is added to absorb some hours, often reducing night paging for the primary region.
Stage 3: Full follow-the-sun
Coverage is split across three or more regions with structured handoff processes. Nighttime pages are eliminated.
Stage 4: Automated and AI assisted distributed response
Automations handle routing, notifications, escalations, and timeline generation. AI assists in reducing diagnosis latency.
Most enterprise Rootly customers operate in Stage 3 or Stage 4.
Checklist for Distributed and Global On-Call Programs
Operational
- define ownership boundaries for services and teams
- adopt follow-the-sun if geography permits
- create handoff standards and artifacts
- use Round Robin to distribute alert load
- minimize escalation depth where possible
Cultural
- remove OOO responders from rotations
- distribute load across holidays
- monitor responder morale and health
Security
- enforce least privilege
- maintain compliance with data residency rules
- adopt dedicated workflows for security incidents
Tooling
- use scheduling systems that support team and service rotations
- adopt platforms that integrate incident response, on-call, and retrospectives
- automate repetitive tasks to reduce cognitive load
Metrics
- track both operational and health metrics
- compare MTTR to benchmark data
- audit handoff quality and ownership transfers
Conclusion
Distributed on-call is the operational response to a global business reality. It replaces ad-hoc night paging and hero-based incident response with structured scheduling, disciplined handoffs, and coordinated workflows across regions and teams. When done well, it improves reliability outcomes for customers and preserves the health of responders who support the system.
Enterprise teams that adopt distributed on-call benefit from automation, AI-assisted analysis, and consolidated incident management platforms such as Rootly. These tools help coordinate regional workloads, enforce consistent escalation rules, and remove manual overhead from retrospectives and follow-up tasks.
Distributed on-call is not simply about having more people available. It is about building a system that reflects how the business operates. Teams that invest in these capabilities position themselves to deliver reliable services to customers anywhere in the world. At Rootly, we help organizations accelerate this journey by providing the automation, AI-native insights, and modern incident workflows required to operate follow-the-sun reliably and sustainably.





