




.svg)









An incident starts. Before anyone can fix anything, the incident commander has to answer a string of questions to kick off the response work. What service is this? What does it depend on? Who owns it? Has this happened before, and what did we do last time? Is there a runbook, and where does it live?
For most teams, the answers are scattered. Some live in a service catalog, some in a wiki, some in the heads of whoever happened to be on call the last time it broke. The commander stitches the picture together by hand while the clock runs. That stitching is dead time, and it happens during the worst possible moment.
The teams that respond the fastest do so because they already have their map drawn. Every service, team, dependency, and owner is defined as an entity in a catalog, and that catalog is wired directly into the place where incident response happens. When something breaks, the context is already attached to it.
That's where the Rootly x Cortex integration comes in, it brings the business entities you've already modeled in Cortex into Rootly’s native catalog, so your incident response is built on the same source of truth as the rest of your engineering org.
Context is the thing responders are short on
Speed in an incident is mostly a context problem. The failure itself is often clear with automated probable root cause analysis and similar incident matching doing a lot of heavy lifting upfront. What can be slow is everything around it; figuring out impact radius, finding the owning team, pulling up the right runbook, remembering whether this is a known issue.
When your catalog entities live inside Rootly, that work is already done. The affected service has clear owners, Slack channels, its repository, and dependencies.
Supercharged with Rootly’s AI Agent, all responders need to do is simply ask for what they need, and the assistant is able to reply with accurate, well-rounded information. Gather similar past incidents impacting the same cluster, or see who was on-call last week for this service to page them for help.
This is how knowledge silos break down. The context that used to live with a handful of senior engineers becomes shared across all responders seamlessly. A responder who has never touched this service before gets the same map as the person who built it. That's the difference between an incident that escalates because nobody knows who to call and one that routes to the right team right away.
You can't improve reliability you can't measure
Long-term reliability comes from learning from your incidents, not just resolving them one at a time. And the quality of what you learn depends on the context you can tie each incident back to. When you have a clear understanding of the business impact behind every incident, the insights you draw across all of them get sharper and more accurate.
When incidents are attached to business entities, you can finally measure reliability the way the business actually experiences it. Which services generate the most incidents? Which teams are carrying the heaviest response load? Where is repeat pain concentrated, and what's the real cost of leaving it unaddressed? Without entities, every incident is a one-off. With them, patterns become visible, and patterns are what let you move from reacting to incidents to preventing them.
That's the shift from reliability as a cost center to reliability as something you can steer. You can point reliability investment at the services that need it, make the case for that work with data instead of anecdotes, and watch the trend line move.
What the integration does
Cortex is where many engineering teams already define their entities: services, teams, agents, domains, and the relationships between them. The integration brings those into Rootly’s catalog without asking you to re-model anything.
You can connect Cortex and Rootly easily in Rootly’s Integration section of the web app. From there, you can map any Cortex Catalog into Rootly’s catalog.
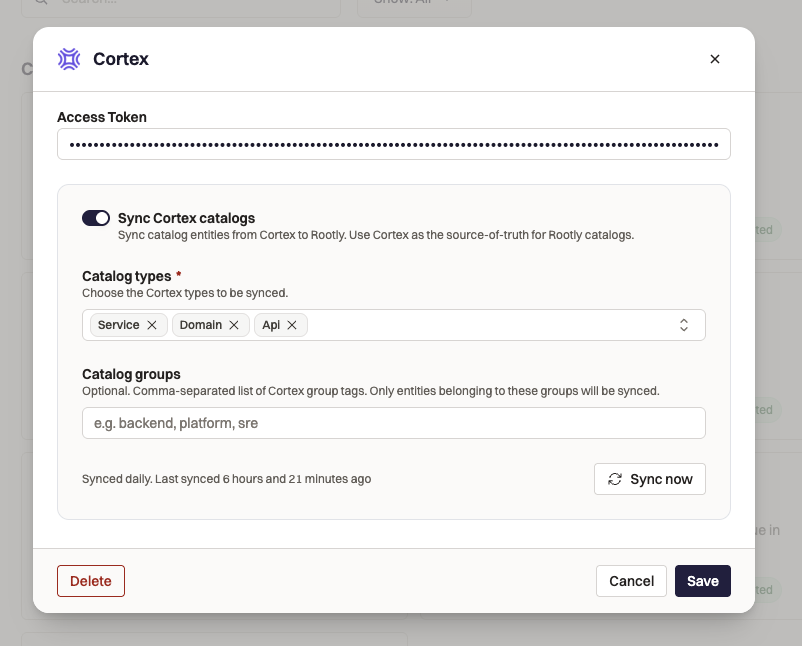
Cortex stays the source of truth. The sync runs on a recurring 24-hour cycle, with an on-demand sync button when you need an update immediately. This allows your commanders and response teams to consistently pull from up-to-date information about your business, and prevents data drift between the two systems.
The result is a single pane of glass. The catalog your engineers already maintain becomes the foundation your incident response and reliability reporting are built on, with no parallel system to keep in step.
What’s next?
Measuring reliability across your business doesn’t stop at incident response. It starts and ends with bringing the right people into the room.
Through your Cortex and Rootly integrations, you’ll be able to build on-call processes across your teams and services to ensure you have complete coverage. From there, you’ll be able to see who's on-call for any service or entity and build scorecard rules to enforce on-call coverage standards across your catalog. All directly in Rootly and Cortex, respectively.
Get started
If you're already on Rootly, you can connect Cortex today. Check out our changelog to learn more, then head to the integrations page in the Rootly web app, map your first Cortex Catalog to a Rootly Catalog, and run a sync.
If you're new to Rootly, start a trial and see what incident response looks like when every responder works from the same map.





