




.svg)









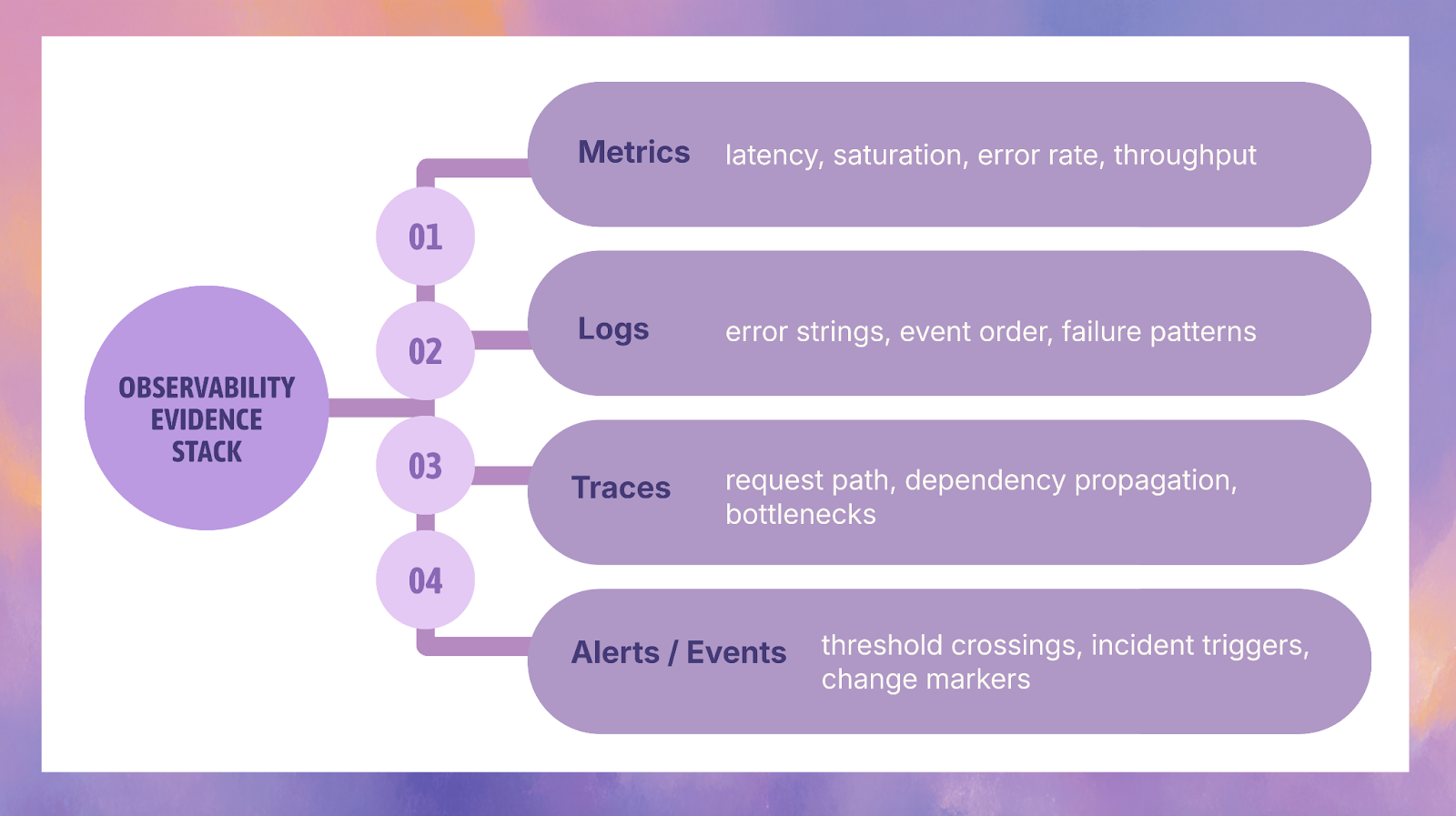
AI SRE integrations are the connections that give an AI reliability system access to the signals, workflow events, ownership data, and operational history it needs to produce useful incident context. In practice, that means connecting observability, on-call, collaboration, ticketing, and change systems so AI can move from scattered symptoms to a grounded picture of what is failing, what changed, who owns it, and what should be checked next. Observability platforms such as Datadog, New Relic, and Honeycomb expose core telemetry types like metrics, traces, logs, and events, which form the raw evidence layer AI SRE depends on.
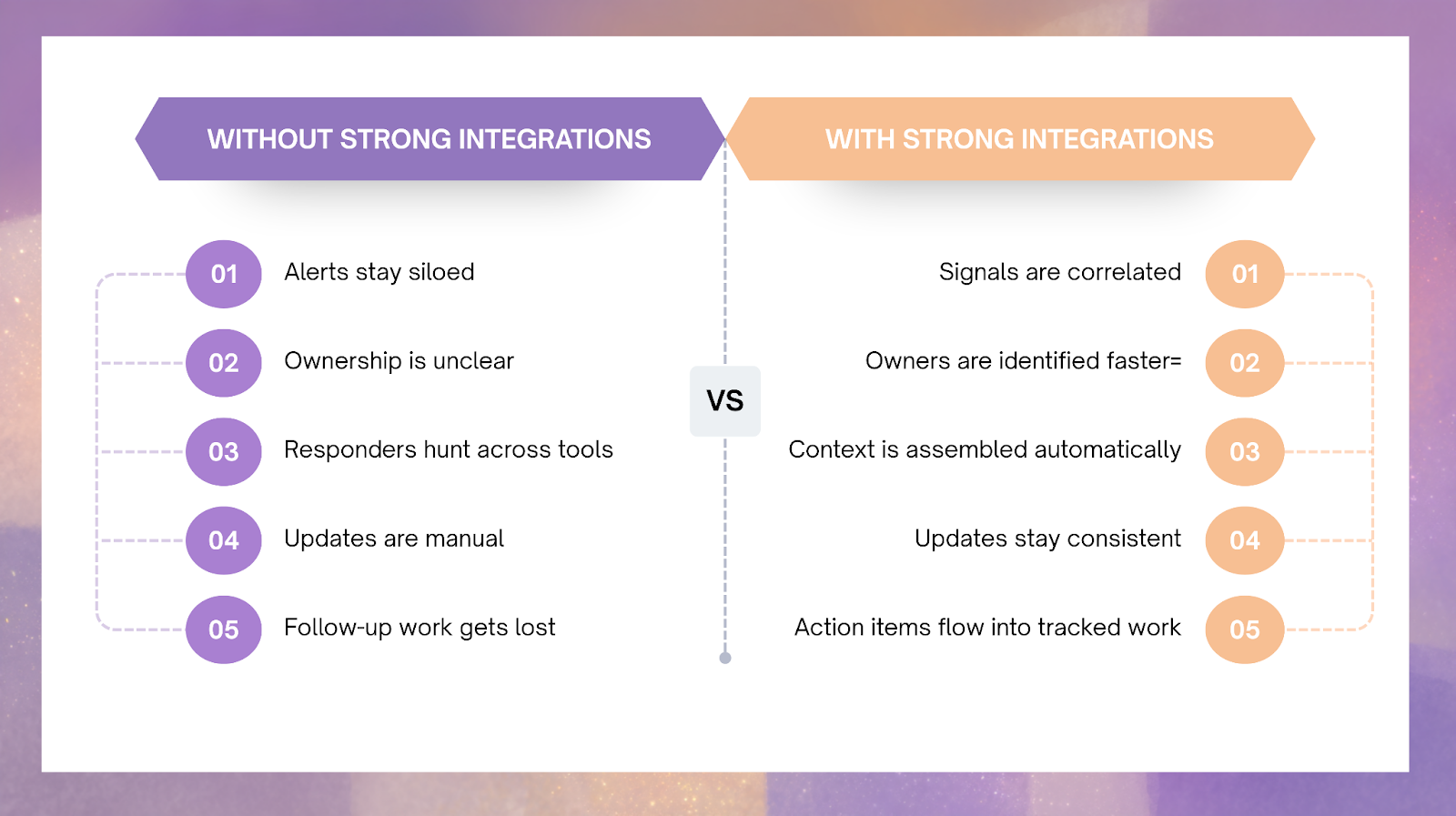
The point of integrations is not coverage for its own sake. The point is to make incident response more operationally useful. When the integration layer is thin, AI can summarize signals but struggles to explain them. When the integration layer is richer, AI can correlate telemetry with routing, collaboration, ticketing, and change history to reduce time to context and improve decision quality.
Key Takeaways
- AI SRE depends on integrated data, not model fluency alone.
- Observability tools provide symptoms, but not the full operational story.
- On-call, collaboration, and ticketing systems give AI the workflow context needed for routing and follow-through.
- Change data matters because incident response gets much faster when the system can answer “what changed?” early.
- The best integration strategy improves context quality before it expands automation.
What an AI SRE Integration Layer Should Actually Do
A strong AI SRE integration layer should make incident evidence computable across systems that were not built to think together. Metrics, logs, traces, alerts, pages, tickets, deploy events, and collaboration messages all describe the same incident from different angles. AI becomes useful when those fragments can be assembled into one operational record instead of being left in separate tools.
That is why the integration layer should support five practical jobs:
- ingest symptoms from observability systems
- ingest routing and responder state from on-call systems
- ingest live coordination signals from collaboration tools
- ingest ownership and follow-through from issue trackers
- ingest change context from deploy, config, and feature systems
If those links are weak, the system may still generate polished text, but it will not generate trustworthy operational context.
The Five Data Source Categories That Matter Most

1) Observability integrations provide the raw evidence
Observability is where most incident evidence starts. Datadog documents metrics as numerical values tracked over time and its APM tools around traces and service performance, while New Relic defines its core model around MELT: metrics, events, logs, and traces. Honeycomb’s OpenTelemetry documentation also supports traces, logs, and metrics. Together, these tools supply the evidence layer AI needs to identify symptoms, compare time windows, and detect likely boundaries of impact.
What these systems contribute is not just “more monitoring.” They contribute different evidence types that answer different incident questions:
- metrics show trend shifts, latency, saturation, and error movement over time
- logs expose event sequences and error patterns
- traces reveal request paths and cross-service propagation
- events and alerts mark important operational moments and threshold crossings
Telemetry is the first layer of usefulness in AI SRE, but telemetry alone is not enough. It can show that something is wrong without showing who should respond, what changed recently, or what work should happen next.
2) On-call and incident systems provide routing and workflow state
On-call and incident tools matter because incident response is not only a diagnosis problem. It is also a coordination problem. These systems hold information such as who is on call, how escalation should happen, which team owns a service, and what stage the incident is currently in.
AI becomes more useful when it can work with this operational state instead of only reading telemetry. That is how it helps reduce misroutes, handoffs, and slow engagement of the correct responders. In practice, this category gives the system access to ownership boundaries, responder assignments, escalation paths, and incident lifecycle state.
3) Collaboration integrations provide the live incident narrative
Slack and Microsoft Teams are not observability systems, but they still carry high-value incident context. During an active incident, they often become the place where teams confirm hypotheses, assign roles, approve next checks, and communicate status. That makes them useful as workflow context, not just messaging channels.
For AI SRE, collaboration integrations help in four ways:
- they preserve coordination events in real time
- they improve timeline capture
- they reduce repeated manual updates
- they help keep summaries aligned with the current state of the incident
This matters because incident response is not only about finding the right graph. It is also about keeping the right people aligned around the same version of reality.
4) Issue tracker integrations turn incidents into owned follow-through
Incident response is incomplete if the learning disappears after resolution. Ticketing systems such as Jira and Linear matter because they convert incident conclusions into assigned work. That includes remediation tasks, prevention work, and follow-up improvements that need to survive beyond the incident channel.
AI SRE becomes stronger when it can connect current incidents to:
- known open issues
- past follow-up tasks
- prevention work that was planned but not completed
- recurring reliability debt
That is how the system starts to support learning, not just response. The value is not only faster incidents. It is stronger continuity between incidents and engineering improvement.
5) Change data explains what changed before impact
One of the most useful integration categories in AI SRE is change context. Deploy events, feature flag updates, configuration changes, and release activity often explain why symptoms appeared when they did. If the system can correlate an incident with a recent change, it becomes much easier to rank plausible hypotheses and narrow the safest next check.
This is where AI moves from generic summarization to useful operational reasoning. A system that only says “error rate increased” is limited. A system that says “error rate increased in checkout shortly after a deploy and ownership maps to the payments platform team” is much more actionable.
Observability Integrations: What Each Type Adds
Datadog
Datadog is useful in AI SRE because its documentation spans metrics, traces, service performance, and correlation between traces and logs through unified service tagging and telemetry connection patterns. That makes it a strong example of how one observability source can support symptom analysis across multiple evidence types.
New Relic
New Relic is useful as an example of full-stack observability because it explicitly organizes data around metrics, events, logs, and traces. That model is relevant to AI SRE because it gives the system multiple evidence forms for the same incident instead of relying on a single signal class.
Honeycomb
Honeycomb is useful in distributed-system and OpenTelemetry-heavy environments because it supports traces, logs, and metrics through OpenTelemetry-based data flows. That makes it a good example of a telemetry source that helps AI work with rich request-level and service-level context.
Grafana
Grafana is useful because many teams rely on it for dashboards and alerting, which means it often becomes part of the human-readable incident surface. In AI SRE terms, Grafana contributes both alert events and visual context that can support incident analysis and documentation.
Why Collaboration and Ticketing Matter More Than They First Appear
It is easy to think of collaboration and ticketing systems as secondary compared with metrics and traces. In practice, they are part of what makes AI SRE operationally useful. Collaboration systems show what the team is doing now. Ticketing systems show what the organization decided to do next.
That means these tools help AI support two important reliability outcomes:
- coordination quality during incidents
- learning continuity after incidents
Without those systems, AI can still assist with symptom analysis. With them, it can support the larger workflow that turns incidents into durable improvements.
What Good AI SRE Integration Coverage Looks Like
A good integration footprint is not “every tool connected.” It is the minimum set of connected sources required to generate a trustworthy context packet and keep follow-through intact.
A practical minimum usually includes:
- one observability source
- one on-call or incident-routing source
- one collaboration platform
- one issue tracker
- one visible source of change data
At that point, AI can usually assemble a meaningful first-pass incident record.
A stronger footprint adds:
- richer service identity across tools
- better ownership mapping
- better change correlation
- cleaner ticket synchronization
- more reliable historical retrieval from incidents and follow-up work
That is when the system starts reducing manual glue work rather than only surfacing information.
Common Integration Mistakes That Weaken AI SRE
Connecting tools without normalizing service identity
If one system calls a service by one name and another system uses a different name, AI will produce fragmented context. The integration may technically exist, but the operational story will still break.
Treating chat as truth instead of context
Slack and Teams are useful, but they should enrich incident context, not replace telemetry, workflow state, or change evidence.
Pulling in stale operational content
An integration layer gets weaker when it exposes outdated runbooks, stale tickets, or obsolete ownership information without any curation.
Expanding breadth before fixing quality
A few reliable sources almost always outperform a broad but inconsistent integration footprint.
Supported Integration Categories at a Glance
How to Prioritize Integrations in the Right Order
The best rollout order is usually based on usefulness during incidents, not on how many systems you can connect.
First priority: observability plus on-call
This gives AI symptoms and routing.
Second priority: collaboration
This improves summaries, timeline capture, and coordination support.
Third priority: issue tracking
This connects incidents to durable engineering follow-through.
Fourth priority: broader change and workflow context
This improves hypothesis quality and helps the system explain what changed.
That sequencing usually gives better results than trying to connect everything at once.
FAQ
What integrations does AI SRE need first?
Start with observability, on-call, and one collaboration platform. That gives the system telemetry, routing, and live workflow context.
Are observability integrations enough on their own?
No. Observability tools explain symptoms, but not the full workflow. AI becomes much more useful when telemetry is connected to routing, collaboration, ticketing, and change data.
Why do Slack and Teams matter for AI SRE?
Because they hold live coordination state during incidents. They help preserve decisions, updates, handoffs, and timeline events.
Why connect Jira or Linear if the incident is already resolved?
Because response is only part of reliability work. Ticketing helps turn lessons and remediation into owned action.
Does broader integration coverage always mean better AI SRE?
No. Better results come from better-connected evidence, not just more connected tools.
Conclusion
AI SRE integrations matter because they determine whether the system works from evidence or from fragments. Observability provides symptoms. On-call systems provide routing. Collaboration tools provide live coordination context. Ticketing systems provide follow-through. Change sources explain what happened just before the failure surface shifted. When those inputs are connected well, AI becomes much more useful for time to context, ownership alignment, and learning capture.
At Rootly, this is where AI SRE becomes operationally practical: the value comes from bringing evidence, workflow, and response coordination together inside the incident process so teams can move faster without losing control.