




.svg)









AI SRE adoption succeeds when teams treat it as an operational rollout, not a feature launch. The goal is not to add another AI interface to the stack. The goal is to improve incident response in measurable ways: faster time to context, cleaner ownership routing, safer mitigations, and stronger learning capture without weakening control.
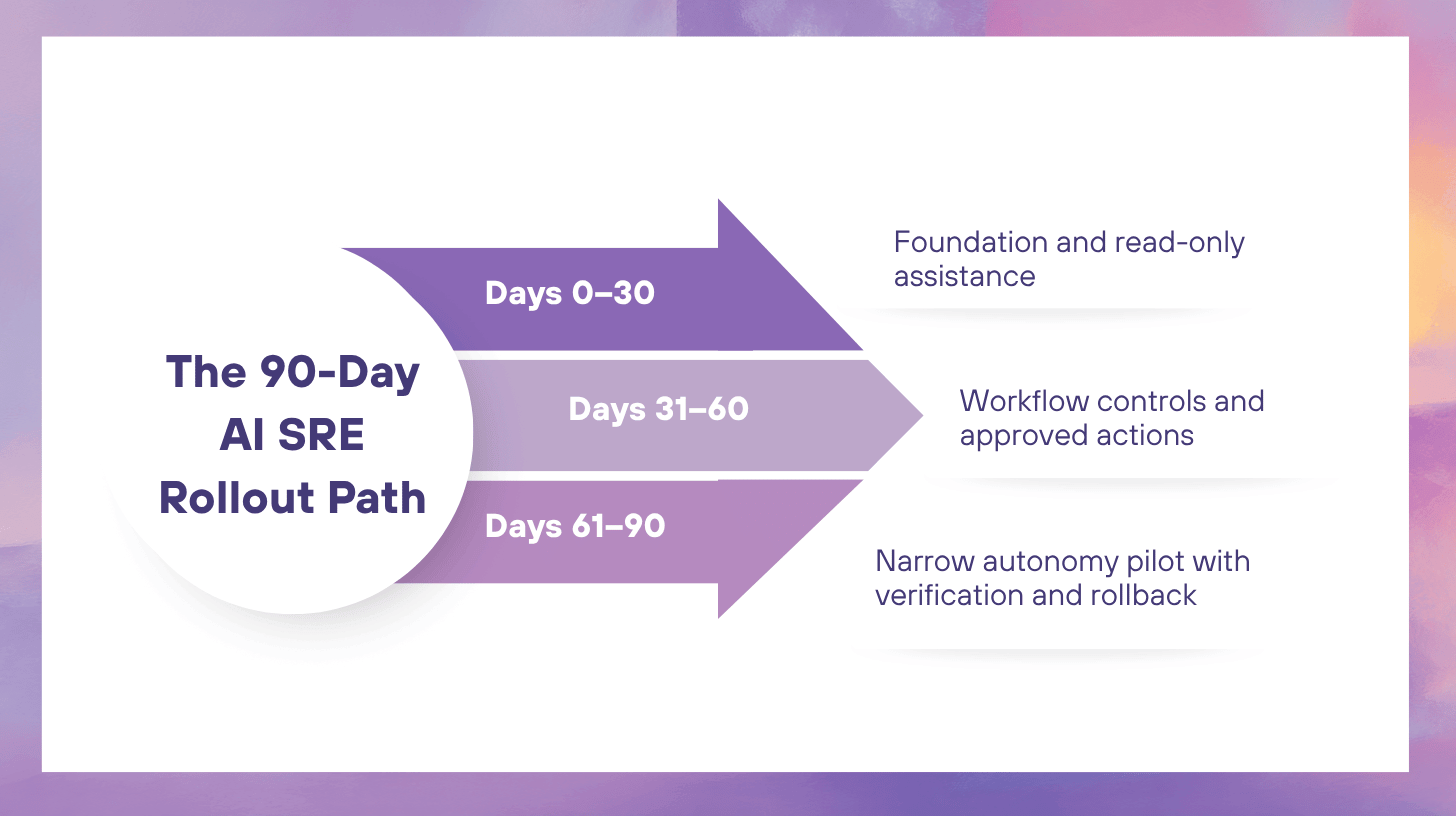
A 90-day rollout works because it forces sequencing. Teams can fix data and workflow foundations first, prove value with read-only assistance next, and introduce controlled actions only after evidence quality, governance, and responder trust are strong enough. That pacing matters. AI SRE fails when execution outruns context quality, or when autonomy arrives before approval paths, rollback rules, and auditability are real.
What follows is a practical adoption plan for SRE, platform, and incident management teams that want to operationalize AI SRE with clear milestones, bounded scope, and production-safe progression.
Key Takeaways
- Start with one incident workflow, not every reliability workflow at once.
- The first 30 days should improve time to context, not automate production changes.
- The second 30 days should operationalize approvals, verification, and incident-grade auditability.
- The final 30 days should pilot narrow, reversible actions for one repeatable incident class.
- Trust grows when evidence quality, ownership data, and runbook hygiene improve together.
What This Rollout Plan Is Designed to Achieve
This rollout plan is built around one practical outcome: incidents become easier to understand, easier to coordinate, and safer to mitigate under pressure. That means the rollout should not be measured by the number of integrations connected or the number of prompts sent. It should be measured by whether responders can move from detection to credible context faster, whether the right people are engaged earlier, and whether actions are proposed and executed with discipline.
The quickest way to lose trust is to make the first milestone too ambitious. Most organizations do not need autonomous remediation in month one. They need a reliable context packet, grounded hypotheses, cleaner routing, and consistent incident records. Those gains create the conditions for every later step.
Scope the Rollout Before You Build Anything
The most important implementation decision is scope. AI SRE rollout should begin with a narrow operating surface.
Start with one team, one workflow, one incident class
Choose:
- one service group or platform area
- one incident workflow inside your current incident process
- one or two frequent incident classes with repeatable symptoms
Good starting points usually have:
- stable service ownership
- recent incident history
- reliable change data
- runbooks that are current enough to trust
- reversible mitigations
Bad starting points usually include:
- poorly owned legacy systems
- incidents with weak instrumentation
- broad infrastructure failures with unclear blast radius
- workflows where actions are irreversible or politically sensitive
Define the first work products
The rollout should produce concrete artifacts, not vague capabilities. For the first phase, define the minimum outputs your AI SRE workflow must create:
- a context packet
- a ranked list of hypotheses
- a draft incident timeline
- suggested next checks
- a structured stakeholder update draft
If the rollout cannot produce these reliably, later phases will compound confusion instead of reducing it.
Phase 1: Days 0–30, Build the Foundation for Read-Only AI SRE
The first month is about trust and data hygiene. AI should help responders understand incidents faster, but it should not execute production actions yet.
Objective for Days 0–30
Reduce time to context by assembling the evidence responders already need, in one place, with enough structure to support verification.
1) Standardize service and ownership data
AI routing and incident context are only as good as your service map. Before adding intelligence, fix the naming and ownership issues that make incident response messy.
Minimum requirements:
- one stable service identifier per service
- consistent environment tagging
- ownership mapping that reflects current on-call reality
- links between services, escalation policies, and critical paths
If one system calls a service “payments-api,” another calls it “pay-core,” and incident responders call it “checkout backend,” AI will produce fragmented narratives. This is not a model problem. It is a data problem.
2) Connect change context early
The first rollout should treat changes as first-class incident evidence.
At minimum, capture:
- deploy events
- configuration changes
- feature flag changes
- incident lifecycle events
This does not belong in a later “integrations” article because implementation depends on deciding what evidence must appear in the first version of the context packet. The actual data-source inventory can live elsewhere. Here, the key point is sequencing: without change context, responders cannot answer “what changed?” quickly, and AI outputs become much less useful.
3) Curate a trusted runbook set
Do not expose the system to every stale operational document in week one. Start with a small, reviewed set of runbooks and incident references.
A trusted set should be:
- owned
- current
- structured enough to retrieve
- explicit about checks, mitigations, and rollback steps
A smaller reliable set is better than broad retrieval across outdated content.
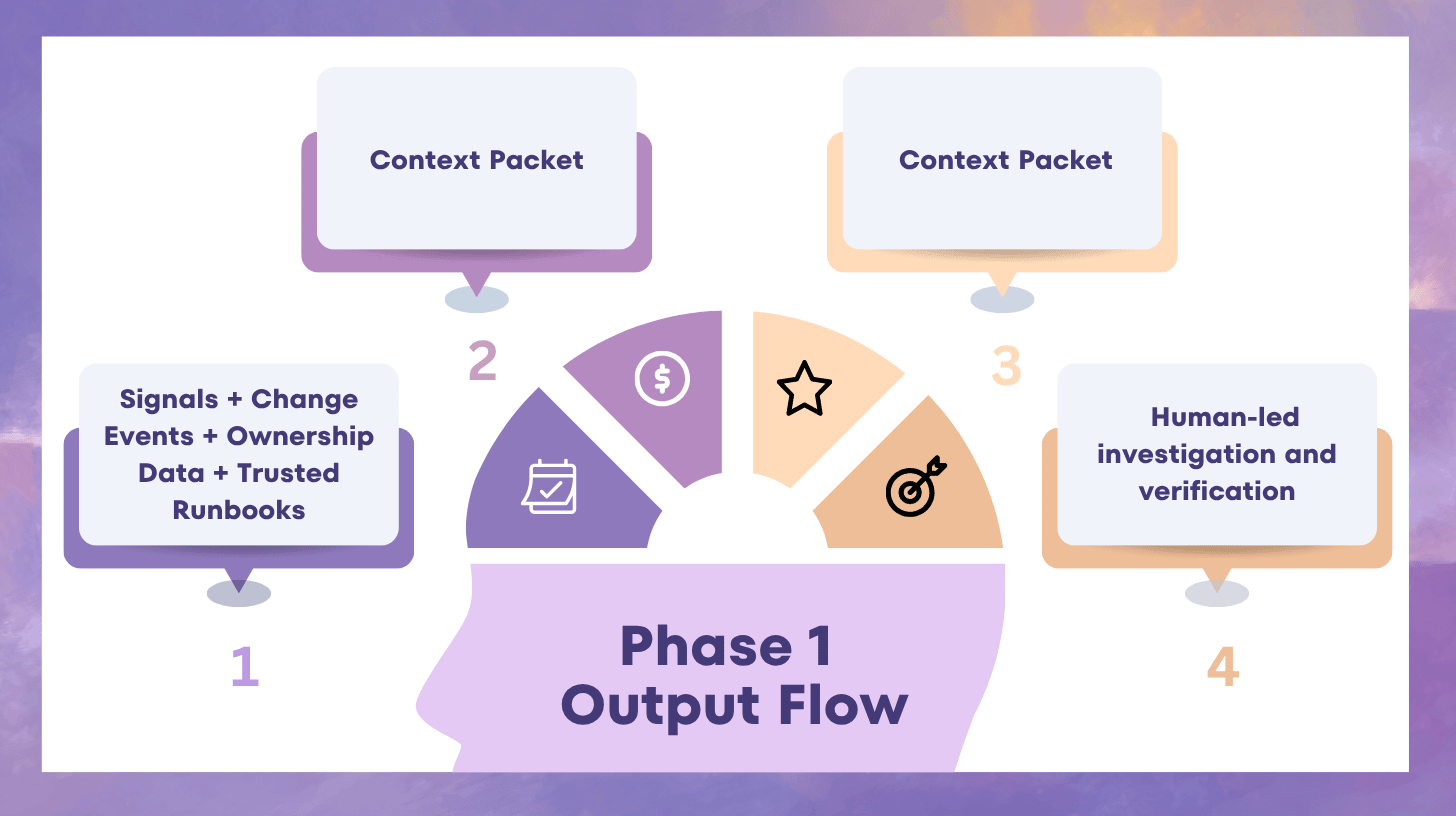
4) Ship a minimum viable context packet
By the end of the first 30 days, the system should produce a read-only context packet for selected incidents.
Minimum contents:
- likely affected service or boundary
- recent changes in scope
- top anomalies by time window
- likely owner or responding team
- similar past incident references
- known safe checks responders can perform next
This is where the rollout begins to create operational value. Responders stop spending the first ten to twenty minutes stitching together the same facts manually.
5) Establish early success metrics
Measure:
- time to context
- correct owner on first page rate
- handoff count
- time to first internal update
- responder adoption of the context packet
The first phase is successful when responders prefer starting from the generated context packet instead of rebuilding context themselves.
Phase 2: Days 31–60, Add Workflow Control and Approved Actions
Once read-only assistance is trusted, the second month introduces controlled action pathways. This is the stage where AI SRE stops being a summarization layer and becomes part of incident execution.
Objective for Days 31–60
Operationalize approvals, verification, and auditability for low-blast, reversible actions.
1) Define action tiers
Not every action should be treated the same. Create action tiers that map to blast radius and reversibility.
A practical structure:
- Tier 0: read-only checks
- Tier 1: approval-gated reversible actions
- Tier 2: high-impact actions requiring stronger controls
Examples of Tier 1 actions:
- rollback of a single deploy
- rollback of a feature flag
- restart of a stateless service unit
- scaling within a pre-approved range
The point is not to maximize execution volume. The point is to make sure the system knows what kind of action is being proposed and which control path applies.
2) Add approvals inside the workflow, not outside it
Approvals should be part of the incident record. If they happen in side channels, governance breaks down and the action history becomes incomplete.
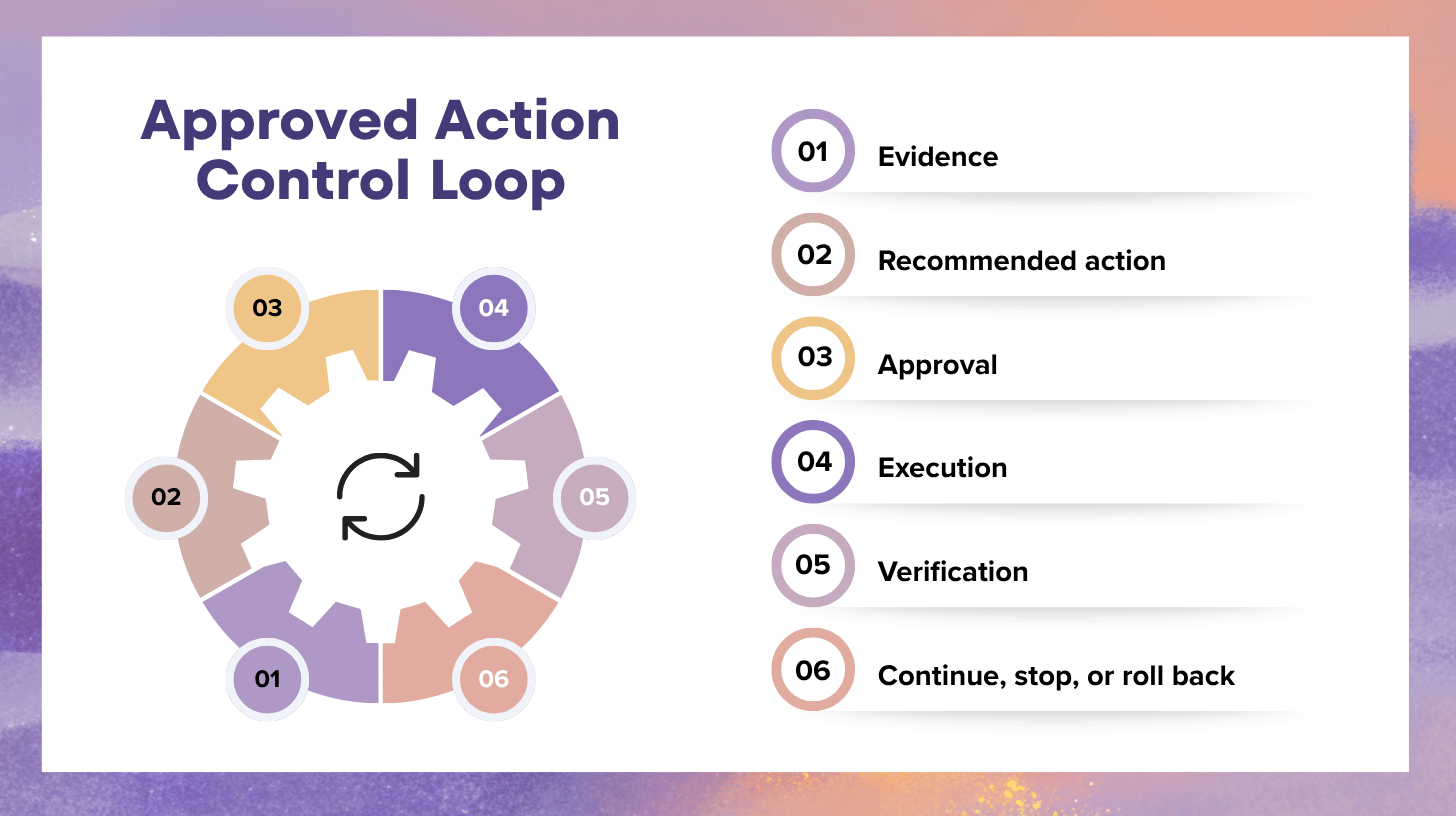
For every approved action, capture:
- who approved it
- what evidence supported it
- what preconditions were checked
- what success signal will confirm improvement
- what rollback path exists
This step matters because it converts AI assistance from “suggestion in chat” into a disciplined incident workflow.
3) Require verification before and after action
Every assisted action should include:
- preconditions
- a success condition
- stop conditions
- rollback readiness
For example, a feature flag rollback should not be treated as safe just because it is reversible. It should still define:
- what metric is expected to improve
- how long improvement must persist
- what degradation would trigger halt or rollback reversal
This is where AI SRE implementation becomes operationally serious. It forces the team to encode what “worked” means before an action is run.
4) Add incident-grade auditability
During this phase, the incident record should automatically capture:
- evidence retrieval
- proposed actions
- approvals
- execution timestamps
- verification outcomes
- rollback events if they occur
A mature rollout does not bolt on audit after the fact. It builds traceability into the workflow while the capability surface is still small.
5) Expand comms support carefully
By this stage, internal comms drafts should be grounded enough to help reduce coordination load.
Useful outputs:
- what is known
- what is being tested
- what action has been approved
- next update time
Keep external messaging approvals separate and deliberate. The second phase is not about full communications automation. It is about consistency and lower coordination toil.
Phase 2 exit criteria
Move to the final phase only when:
- approved actions are consistently verified
- responders trust the recommendation quality
- rollback logic is defined before execution
- audit logs are complete enough for review
- policy and approval flows are not slowing incidents unnecessarily
Phase 3: Days 61–90, Pilot Narrow Autonomy for One Repeatable Incident Class
The third month is not about broad autonomy. It is about proving that one narrow, reversible workflow can run safely under explicit conditions.
Objective for Days 61–90
Pilot a limited autonomy path for one frequent, low-blast incident class with strong instrumentation and clear rollback rules.
1) Choose the right pilot
Select one failure mode that is:
- frequent enough to evaluate
- clearly scoped
- supported by strong telemetry
- backed by a known-safe runbook
- reversible within minutes
Examples might include:
- a single service instance restart for a known bad state
- a feature flag rollback tied to a known symptom cluster
- traffic shift away from a degraded zone under clear health thresholds
Avoid anything involving:
- data integrity risk
- security posture changes
- broad network policy
- multi-service cascading actions
2) Convert the runbook into machine-enforced steps
The pilot should not rely on “AI judgment” alone. It should use a tightly defined execution path:
- trigger conditions
- evidence requirements
- blast radius limits
- canary or narrow scope first
- stop conditions
- rollback conditions
- escalation triggers
This keeps the autonomy narrow and auditable.
3) Start with canary scope
Even reversible actions should start in the smallest practical blast radius.
For example:
- one instance before fleet-wide restart
- one region before wider failover
- one feature segment before full rollback expansion
The goal is to verify quickly without amplifying risk.
4) Instrument takeover conditions
Autonomy should degrade safely when conditions worsen or confidence drops.
Define human takeover triggers such as:
- verification signals fail to improve
- contradictory evidence appears
- unexpected downstream regressions begin
- action count exceeds the pilot’s allowed sequence
- the incident exceeds the pilot’s intended blast radius
This is how the rollout stays disciplined. The system does not “try harder” when uncertainty rises. It returns control.
5) Evaluate the pilot weekly
Do not wait until day 90 for review. Inspect:
- action success rate
- rollback rate and rollback time
- stop-condition activations
- human takeover frequency
- responder trust and reviewer feedback
A narrow pilot is successful when the team can explain exactly why it is safe, where it succeeded, and where it stopped itself appropriately.
The Operating Model That Supports the Rollout
A 90-day plan works only if people roles are clear.
Required human roles
At minimum, define:
- rollout owner
- SRE or platform lead
- security or governance reviewer
- incident process owner
- runbook owner for each pilot workflow
This does not need a large committee. It needs clear responsibility.
Weekly review cadence
Each week should include:
- incidents where AI SRE assisted
- incidents where it should have assisted but did not
- evidence quality issues
- ownership or runbook gaps
- policy friction that blocked useful work
- candidate improvements for the next week
A weekly loop prevents the rollout from becoming theoretical.
Common Rollout Mistakes
Starting with autonomy instead of context
If the team does not trust the context layer, every later action proposal will be questioned.
Using stale operational knowledge
Weak runbooks and outdated ownership data create confident but wrong recommendations.
Treating approvals as paperwork
Approvals should shape safe execution, not become a disconnected compliance step.
Expanding scope too early
One successful pilot does not justify broad autonomy. Scale should follow evidence, not excitement.
Measuring only MTTR
Early rollout success shows up first in time to context, routing quality, action verification, and coordination overhead.
What Success Looks Like at Day 90
By the end of 90 days, a strong AI SRE rollout should produce visible operational changes.
You should see:
- responders starting incidents from a context packet instead of manual hunting
- fewer misroutes and cleaner ownership engagement
- approved actions executed through governed workflow rails
- verification and rollback discipline becoming normal behavior
- one narrow autonomy pilot with clear safety boundaries and measurable outcomes
- incident records that are more complete while requiring less manual reconstruction
What you should not expect:
- autonomy across all incident types
- total removal of human decision-making
- perfect MTTR improvements across every service and severity
- broad trust if foundational data quality is still weak
The point of the first 90 days is not maximum automation. It is repeatable control and measurable operational improvement.
FAQ
Where should an organization start if incident workflows are inconsistent?
Start with the workflow that already has the cleanest ownership data, clearest runbooks, and most repeatable incident patterns. AI SRE rollout works best when the first surface is stable enough to measure.
How many incident classes should be included in the first 90 days?
Usually one or two. More than that spreads review effort too thin and makes it harder to identify whether improvements came from the rollout or from unrelated changes.
When should approved actions begin?
Only after the team trusts the read-only context output and can verify that recommendations are evidence-backed. Approved actions should follow trust, not precede it.
What should be automated first?
Start with context assembly, timeline capture, ownership suggestion, and draft internal updates. Those reduce toil without creating immediate production risk.
What is the right outcome for the first autonomy pilot?
A successful pilot proves bounded execution, verification discipline, and clean escalation back to humans when conditions change. Safe limitation is a better outcome than broad action volume.
Putting AI SRE Into Operational Practice
AI SRE implementation is a sequencing problem. The teams that succeed do not start by asking how much automation they can turn on. They start by asking what responders need in the first minutes of an incident, what evidence the system must show, what actions are truly safe to encode, and what controls must exist before production changes are allowed. That is how a rollout becomes operationally credible.
A disciplined 90-day rollout moves through three clear stages: read-only context assistance, approval-gated execution, and a narrow autonomy pilot for one repeatable failure mode. Each stage builds on the last. Each stage earns trust with measurable improvements. Each stage strengthens the workflow instead of adding noise to it.
At Rootly, we understand that AI SRE only works when it fits the incident workflow teams already rely on, with evidence, policy controls, and operational discipline built into every phase. The most practical rollout path is one that reflects your services, approval model, and recurring incident patterns, with each stage expanding only after trust and control are established.